GANs에서 WGAN-GP Loss는 LSGAN Loss와 함께 가장 많이 쓰이는 loss이다. 이전의 loss 들의 문제점을 많이 해결했고 논문에서는 잘 작동하는 이유를 수학적으로 후련하게 알려준다. 하지만 수학이 좀 많이 쓰인다...한국어로 된 WGAN 자료가 많이 없는데 혹시나 도움 됐으면 한다.
수학이 상당히 헤비하게 나오는데 붙들고 좀만 머리굴리면 이해 되는 수준일 것이라 생각한다. 사실 나도 잘 이해했는지는 모르겠다. 내가 이해한 수준에서 리뷰해보겠다.
(현재 수학을 배우는 중이어서 이해도가 높아질 때마다 수정하고 있습니다. 의도치 않게 많은 분들이 이 글을 찾아오시고 있습니다. 이상한 부분은 가차없이 태클 걸어주시면 감사하겠습니다.)
빠른 요약
- Motivation
- GAN에서는 real, fake의 두 분포 간 거리를 KL, JS 등의 미분가능한 divergence를 loss로 채택했다.
- 하지만 지금 사용되는 divergence들은 두 분포가 엄청 멀 때와 조금 멀 때를 구분 못하는 문제가 있다.
- 따라서 학습이 불안정한 원인이 된다.
- Solution
- EM(Wasserstein-1) distance라는 멋진 수학적 도구가 있다.
- 얘는 분포가 엄청 멀면 큰 값, 적당히 멀면 작은 값을 뱉는다.
- 이걸 GAN에 적용해서 WGAN을 만들었다.
- 적용할 때 제약조건이 생기는데 그걸 만족시키기 위해서 약간의 트릭도 첨가했다.
- WGAN의 loss는 이미지 퀄리티가 좋고 나쁨을 잘 표현한다. 좋으면 낮게, 나쁘면 높게 나온다.
- 위에서 말한 트릭을 해결해서 WGAN-GP라는 논문을 또 썼다.
이 글의 구조
수학적으로 받아들일 정도로 이해하는 것을 목표로 하기에 최대한 self-contained가 되도록 만들었다. (하지만 실패했다.)
- 개요
- KL, JS는 두 분포가 멀면 어떻게 동작하길래 거리를 구분 못한다고 하나?
- KL, JS는 어떤 수학적 조건이 부족해서 저렇게 작동하나? 이 논문에서 주목한 property는 무엇인가?
- Distance 소개
- 각각의 distance의 정의는 무엇이고, 왜 GAN에 쓰이며, 문제점은 무엇인가?
- Wasserstein-1 distance는 무엇이고 왜 문제점을 해결하는가?
- 수학적 배경: 개념은 알겠는데 뭐가 그렇게 애매해서 정의를 이렇게 복잡하게 만든 건가? 아니 사실 개념 이해도 잘 안 된다. 뭐가 이해가 안 됐는지도 모르겠다. (이 글을 쓴 이유)
- WGAN
- W-1 distance를 어떻게 GAN에 적용했는가? 그냥 loss만 바꿔끼면 되는가? 뭐가 난관이었나? 적당한 loss 하나 찾아서 바꿔꼈다고 탑티어 논문인가? 어떤 insight를 주는가?
- 실험 결과
- 그래서 WGAN은 잘 하나? 왜 잘 하나?
Notations
수학이 많이 나오는 논문 들을 읽을 때 힘든 점 중 하나가 notation이 달라서 notation을 이해하는 데에도 상당한 시간을 쓴다는 것이다. 글을 시작하기 전에 정리 한 번만 하자.
$\mathcal{X}$ : a compact metric set, $x$가 가질 수 있는 값들을 모아놓은 집합이다.
$\mathbb{P}$ : 분포 또는 확률 measure이다. $\mathbb{P}(x)$라 하면 분포 $\mathbb{P}$에서 $x$가 등장할 확률이 된다.
$P$ : pdf(Probability Density Function)이다. $P(x)$가 확률이 아니라 $\int P(x)dx$가 확률이다!! ($\int Pd\mu$)
$Supp(f)$ : support라고 한다. 함수(mapping) $f$가 0이 되지 않게 하는 $f$의 정의역의 부분집합이다. 예시로 ReLU는 실수 전체가 정의역이지만 양수일 때만 0이 아닌 값을 가지므로 $Supp(ReLU) = \mathbb{R}^+$가 된다.
나머지는 등장할 때마다 설명하겠다!
개요
Unsupervised learning의 대표적인 예제인 Maximum Likelihood Estimation(MLE)은 아래의 식을 푸는 것으로 나타낼 수 있다.
$\theta$로 parameterized된 분포들의 모임 $(P_\theta)_{\theta \in \mathbb{R}^d}$이 있을 때, 실제로 수집한 데이터 샘플 $\{x^{(i)} \}_{i=1}^m$에 대하여
$$\max_{\theta \in \mathbb{R}^d} {1 \over m} \sum_{i=1}^m \log P_\theta (x^{(i)})$$
(연속 확률 분포에서는 likelihood를 measure $\mathbb{P}$가 아니라 density $P$로 정의한다.)
식의 의미를 표현하자면 "Data 덩어리 $\mathcal{X}$를 가장 잘 표현하는 분포 $\mathbb{P}_\theta$를 찾아라!" 정도 되겠다. 이 문제를 푸는 건 KL-divergence를 최소화하는 것과 동치라고 한다.
KL-divergence는 분포들의 집합 $\{\mathbb{P}\}$에서 정의된 하나의 거리와 같다. MLE를 잘 푸려면 그의 동치인 KL-divergence가 0으로 잘 수렴해주어야 하는데, 애초에 두 분포의 support가 겹치지 않으면 KL이 발산하기 때문에 계산조차 불가능하다. 우리가 풀고자 하는 이미지 생성 문제는 이미지들이 아주 고차원에 분포해있기 때문에 이런 문제들이 더 빈번하게 발생한다.
Support가 강제로 겹치게 해줄 수 있다. 기존 이미지에 가우시안 등의 노이즈를 추가해주면 아래 그림처럼 조금이나마 겹치게 할 수 있다. 하지만 그렇게 좋은 해법은 아니고 생성된 이미지도 굉장히 흐릿하다고 한다.


이를 해결해준 것은 GAN이다. 분포를 직접 예측할 필요가 없기 때문에 열심히 prior를 주지 않아도 모델에 데이터만 때려박아도 된다. 이미지 공간을 Generator의 input 공간인 $\mathcal{Z}$에 embedding한 효과도 볼 수 있다. 실제로 $\mathcal{Z}$는 100차원 정도로 이미지에 비하면 매우 저차원이다. 하지만 GAN은 이미지가 조금만 복잡해져도 학습 난이도가 매우 높아진다. 학습이 매우 불안정한데 이를 metric이 원인인 것으로 보고 수학적으로 해결한 것이 WGAN이다.
Kullback-Leibler Divergence
"분포 사이의 거리"를 측정할 때 가장 많이 쓰이는 metric은 KL(Kullback-Leibler) Divergence일 것이다. (이제부터 거리를 거리라고 안하고 metric이라 하겠다.) 기존의 metric들이 어떤 문제점이 있었는지 KLD를 예시로 한 번 살펴보자.
일단 KLD는 다음과 같이 정의된다.
$$KL(\mathbb{P}_r || \mathbb{P}_g) = \int \log \left ( {P_r(x) \over P_g(x)} \right ) P_r(x) d\mu (x)$$
여기서 $\mu$는 $\mathcal{X}$에서 정의된 보조 measure이다. 여기선 $\mu(x)=x$로 생각해도 된다.
식을 봤을 때 가장 불안한 요소라 하면 분모에 있는 $P_g$이다. 이 때문에 $P_g(x)=0$이지만 $P_r(x) \neq 0$인 곳이 생긴다면 발산하게 된다. 논문에서는 이런 일이 저차원에서 빈번하게 일어난다고 한다.

빨간색 부분이 아주 넓다면 KL을 계산하기 좋은 상황이겠지만 실제 데이터가 그렇게 만만했으면 이런 논문이 안 나왔을 것이다.
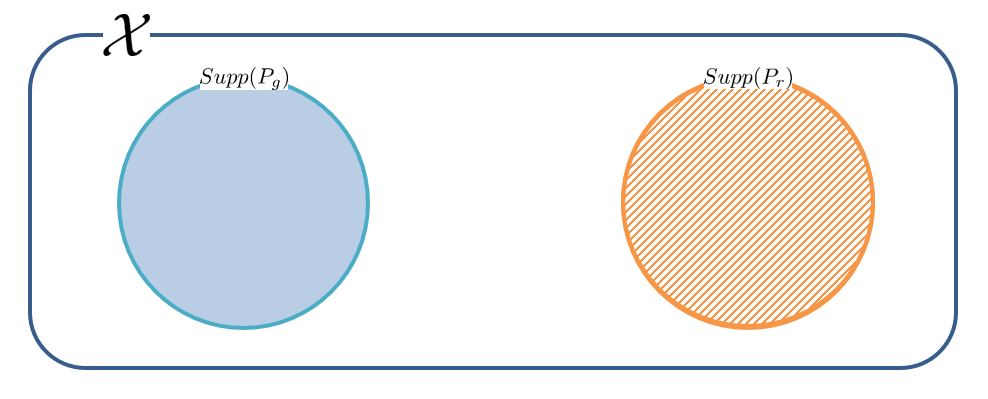
보통 학습 초기에 위 그림처럼 support가 겹치지 않는 상황이 꽤 발생하고 이렇게 되면 model이 의미 없는 gradient를 생성해 학습이 진행되지 않는다.
그래서 이 논문은
1. 얌전히 수렴하고
2. 매끄러운
metric인 $\rho(\mathbb{P}_\theta, \mathbb{P}_r)$를 정의하는 것을 목표로 한다.
1) 얌전히 수렴하는
논문 2페이지 주석에 $\rho$가 유도한 위상이 weak하다는 것의 뜻이 나온다.

$\rho$가 유도한 위상이 $\rho'$가 유도한 위상보다 약하다는 것은 $\rho'$에서 수렴하던 수열들이 $\rho$에서도 수렴하는 것이다. 이해가 될 듯 말 듯 할 것이다. 수렴성의 위상수학적인 정의를 알아야 한다.
일단 우리가 배운 수렴은
$$\exists\lim_{n \rightarrow \infty}x_n$$
이다. 그냥 극한값이 real line위에 존재하기만 하면 된다. 이는 많은 것이 생략된 정의이다. 해석학에서는 $\epsilon - N$ 논법으로 정의한다.
$$[x_n \rightarrow x] \iff [\forall \epsilon>0, \exists N \in \mathbb{N}, \forall n > N: |x_n - x| < \epsilon]$$
수식이 좀 푸짐해보이는데 실제로 수학과의 첫 난관이라 한다. 아무튼 이 정의는 $x_n$과 $x$사이의 거리를 재는 데에 유클리드 거리 $|x_n - x|$를 사용한다. 위상수학에서는 거리 없이 정의할 수 있다.
$$[x_n \rightarrow x] \iff [x \in ^\forall \text{open } U \subseteq X, \exists N \in \mathbb{N}, \forall n > N: x_n \in U]$$
$x$를 포함한 임의의 열린집합 $U$가 $\{x_n\}$의 유한개를 제외한 모든 점을 다 가지고 있으면 된다.
여기서 열린집합이라는 것이 발목을 잡는다. 어떤 metric $\rho$가 위상을 유도했다는 것은 $\epsilon$-공 $B_\rho (x, \epsilon)$들의 합집합을 열린집합으로 하겠다는 것이다. 지금은 열린집합의 정의가 $\rho$에 따라 달라질 수 있다는 것만 알아두면 된다. 어떤 위상에서 열린집합이 적을 수록 수열이 수렴을 잘 한다. 왜냐하면 모든 열린집합이 저 조건을 만족해야 하는데 그 조건을 만족해야 할 친구들이 적어지기 때문이다. 많은 수열들을 수렴하게 하는 metric $\rho$를 찾는 것이 우리의 목표이다.
2) 매끄러운
뒤의 정리에 나오지만 generator 함수가 연속이면 여기서 소개할 metric은 연속인 동시에 거의 모든 곳(많아야 가산 개를 제외한 모든 점)에서 미분가능하다. 뉴럴넷은 연속이기 때문에 metric이 연속이기만 하면 매끄러울 것이다. "연속성"에 대해 알아보자.
일단 우리가 배운 연속의 정의는
$$\lim_{x\rightarrow a} f(x)=f(a)$$
이다. 그래프를 그렸을 때 이어져있기만 하면 된다. 이도 역시 많은 것이 생략된 정의이다. 해석학에서의 연속은 $\epsilon - \delta$ 논법으로 정의한다.
$$[x\rightarrow a \implies f(x)\rightarrow f(a)] \iff [\forall \epsilon > 0, \exists \delta > 0: |x-a| < \delta \implies |f(x)-f(a)| < \epsilon]$$
하지만 이 정의에도 문제점이 있다. 바로 $|f(x)-f(a)|$를 계산해야 된다는 것인데 지금 $f(x)$, $f(a)$는 확률분포이다. 확률분포끼리 거리를 계산하는 것에는 다양한 방법이 있다. 그럼 연속성이 "거리"라는 것에 대해 의존성을 가지게 된다. 그래서 수학자들이 좀 더 일반적인 정의를 생각해냈다.
$$[x\rightarrow a \implies f(x)\rightarrow f(a)] \iff [f(a) \in ^\forall \text{open } V \subseteq f(X): x \in f^{-1}(V) \text{ is also open in } X]$$
말로 풀면 "$f(a)$를 포함한 모든 열린집합들이 역상도 열린집합"이다. 열린집합과 역상에 대한 이해가 필요하지만 넘어가자. 이는 바로 위의 정의와 아무 상관 없는 것처럼 보이지만 놀랍게도 metric이 주어져 있으면 동치이다.
이걸 지금 상황에 적용해보면
$$[\theta_t \rightarrow \theta \implies \mathbb{P}_{\theta_t} \rightarrow \mathbb{P}_\theta] \iff [\mathbb{P}_\theta \in ^\forall \text{open } V \subseteq \{\mathbb{P}_\beta\}: \theta \in f^{-1}(V) \text{ is also open in } \{\theta_\alpha\}]$$
가 된다. $\theta \mapsto \rho(\mathbb{P}_{\theta_t}, \mathbb{P}_\theta)$가 연속임을 보여야 하지만 $\rho$가 유도한 위상에서는 $\mathbb{P}_\theta \mapsto \rho(\mathbb{P}_\theta, \cdot)$는 연속이다. 따라서 $\theta \mapsto \mathbb{P}_\theta$가 연속임을 보이는 것만으로도 충분하다. $\rho$가 유도한 위상(열린집합을 정의해준다)에서 위 식만 만족하면 된다는 뜻이다.
여기도 역시 공역에서의 열린집합이 적을수록, 정의역에서의 열린집합은 많을수록 이득이다. $\theta \mapsto \mathbb{P}_\theta$가 연속이 되게 해주는 metric을 찾는 것이 목표이다.
Contributions
이 논문을 요약하자면 다음과 같다.
- EM distance를 소개하고 GAN에 적용한 WGAN을 제안
- 왜 WGAN이 mode collapsing이 없는지 이론적/실험적 증명
- EM distance로 만든 W1 loss가 WGAN으로 생성한 이미지 퀄리티와 correlate 되어 있음을 보이고, 따라서 JS 등 다른 divergence보다 더 reasonable한 loss임을 주장
- 이미지 퀄리티와 correlate: 이미지가 잘 나왔으면 loss가 낮고, 별로면 높고
나에겐 세 번째 contribution이 가장 intuitive했다.
Different Distances
Metric들을 비교하기 전에 notation을 잠깐 정리해보자.
$\mathcal{X}$ : a compact metric set
$\Sigma$ : Borel subsets of $\mathcal{X}$
$\text{Prob}(\mathcal{X})$ : the space of probability measures defined on $\mathcal{X}$
시작하기도 전에 막혀 버렸다. 하나씩 차근차근 살펴보자.
Compactness
사전식 뜻은 "빽빽함"이다.
위상공간 $\mathcal{X}$를 덮는 임의의 열린덮개들이 있을 때, 그 중 유한개의 부분 덮개들을 뽑아서 $\mathcal{X}$를 항상 덮을 수 있으면 위상공간 $\mathcal{X}$는 compact하다 한다.
$\mathcal{X}$를 덮은 열린집합들의 모임(덮개)가 있을 때, 그 중 몇 개만 뽑아서 $\mathcal{X}$를 덮어봤는데 다시 덮이더라 하면 compact인 것이다. 굉장히 두루뭉술한 정의 같지만 Heine-Borel 정리라는 것에 의해 직관적으로 생각할 수 있다.
해당 정리에 의하면
- 경계가 있고
- 그 경계를 포함
하기만 하면 compact라 부를 수 있다. (유계된 닫힌집합)

개인적인 생각으로는 수학에서 compactess 개념은 열린집합 기반의 추상적인 위상수학과 미분적분학을 연결해주는 역할을 하는 것 같다. 해석학에서는 compactness 이후로부터 미분적분학에 등장한 개념들을 거의 다 유도할 수 있게 된다.
Borel Subsets
설명하려면 글 한 바닥이 나온다. 그래서 따로 정리해놨다. 이 글을 읽기 위해 꼭 알아야 하는 내용은 아니지만 막상 넘기자니 아쉬워서 공부해보고 글로 하나 써놨다.
왜 하필 Borel Set일까?
Mathematics | 왜 하필 Borel Set일까?
Reference https://jjycjnmath.tistory.com/150 https://www.slideshare.net/ssuser7e10e4/wasserstein-gan-i http://iseulbee.tistory.com/attachment/cfile21.uf@213DA24658C01012058757.pdf https://en.wikiped..
haawron.tistory.com
Borel 집합은 $\mathcal{X}$의 measurable한 부분집합인데, 읽고 쓸 수 있는 것은 모두 다 measurable하다고 생각할 수 있늬 이외의 경우는 생각하지 말도록 하자. 확률을 정의할 때 내일 비가 올 확률이 30%면 안 올 확률은 70%여야 한다. 확률 계산할 때 문제가 안 생기도록 이러한 제약들을 수학적으로 정의했고 그들을 만족하는 집합이다.
쉽게쉽게 가도 될 것 같지만 "'과녁의 한 점을 맞힐 확률은 0'인 게 말이 되냐"를 반박하다가 복잡해진 역사가 있다.
Probability Measure
확률측도라고 하며 웬만해선 확률분포인 $\mathbb{P}$와 동일하게 생각해도 문제가 없다. $\mathcal{X}$ 위에 정의되어 엄밀하게 확률을 측정하도록 만든 수학적 도구이다. 집합을 주면 확률로 바꿔주는 함수 같은 걸로 생각할 수 있다.

두 말을 섞어 써도 이해하는 데에는 크게 문제 없다.
이제 본격적으로 두 분포 $\mathbb{P}_r, \mathbb{P}_g \in \text{Prob}(\mathcal{X})$에 대한 metric들을 정의할 수 있게 됐다.
The Total Variation (TV) Distance
$$\delta(\mathbb{P}_r, \mathbb{P}_g) = \sup_{A \in \Sigma} |\mathbb{P}_r(A) - \mathbb{P}_g(A)|$$
이것도 차근차근 살펴보자.
Supremum (sup)
우리말로 최소상계를 의미한다. 그림을 보면 바로 이해 된다. 참고로 $\inf$는 infimum이고 최대하계를 의미한다.
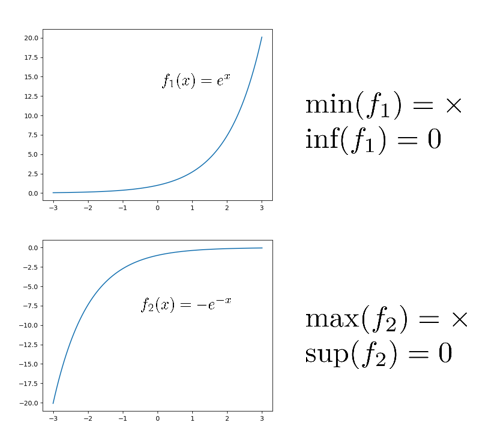
어떤 함수의 치역의 모든 원소보다 크거나 같은 값이 있다면 그 값을 상계, 작거나 같은 값이 있다면 하계라 부른다. $e^x$를 예로 들면 하계는 $0$도 될 수 있고 $-182$도 될 수 있다. 하지만 그 중 최댓값은 $0$이므로 $e^x$의 최대하계는 $0$이 되겠다.
$\min(e^x)$는 정의가 안 되지만 $\inf(e^x)=0$이다.
$\max(-e^{-x})$는 정의가 안 되지만 $\sup(-e^{-x})=0$이다.
지금은 $\sup$과 $\max$를 같다고 생각해도 무방하다.
한편, distance의 의미를 해석해보면 아래 그림과 같다.

$A$를 초록색 박스와 같이 잡으면 $|\mathbb{P}_r(A) - \mathbb{P}_g(A)| = 0.4$이지만 빨간색 박스와 같이 잡으면 $|\mathbb{P}_r(A) - \mathbb{P}_g(A)| = 0.35$가 된다. 다른 방법으로 $A$를 결정할 수는 있지만 $|\mathbb{P}_r(A) - \mathbb{P}_g(A)|$의 값이 $0.4$를 넘지는 않는다. 따라서 $\delta(\mathbb{P}_r, \mathbb{P}_g) = 0.4$라 할 수 있다.
만약 두 분포간 support가 겹치지 않게 되면 total variation는 1이 되게 된다.

애초에 확률은 1을 넘길 수 없으므로 1이 최댓값인 것은 분명하다.
The Kullback-Leibler (KL) Divergence
$$KL(\mathbb{P}_r || \mathbb{P}_g) = \int \log \left ( {P_r(x) \over P_g(x)} \right ) P_r(x) d\mu (x)$$
$\mu$는 $\mathcal{X}$위에서 정의된 또 다른 measure이다. $P_r = {d\mathbb{P}_r \over d\mu}$이며, 이를 Radon-Nikodym Derivative라고 한다.
어떤 수조에 물이 담겨 있다고 생각해보자. 물의 밀도를 알고 싶다면 어떻게 해야 할까? 수조에 눈금이 있다면 물의 부피를 잴 수 있고 물의 무게도 쉽게 잴 수 있다. 그러면 이 둘 사이의 관계를 표현할 수 있다.
(물의 무게) = (물의 밀도) x (물의 부피)
여기서 물의 부피 역할을 하는 것이 $\mu$, 물의 밀도 역할을 하는 것이 $P_r$ 이다. 이에 대한 좀 더 자세한 설명은 여기를 참조하면 되겠다.
무시하고 $\mu(x) = x$로 생각해도 이 논문을 읽는 데에는 크게 지장이 없다.

아무튼 차치하고 하고 싶은 말은

두 분포의 Support사이의 거리가 멀면 KL이 발산한다는 것이다.
(사실 정의가 안 된다고 하는 게 맞다)
The Jensen-Shannon (JS) Divergence
JS는 KL을 이용해 간단하게 표현할 수 있다.
$$JS(\mathbb{P}_r || \mathbb{P}_g) = {1 \over 2} KL(\mathbb{P}_r || \mathbb{P}_m) + {1 \over 2} KL(\mathbb{P}_g || \mathbb{P}_m) \text{, where } \mathbb{P}_m = (\mathbb{P}_r + \mathbb{P}_g)/2$$
(논문에 1/2이 빠졌다.)
$\mathbb{P}_m = 0$이면 $\mathbb{P}_r = \mathbb{P}_g = 0$이기 때문에 발산할 일은 없다.
$$\because \mathbb{P}_m = 0 \Longrightarrow \mathbb{P}_r = -\mathbb{P}_g \ge 0, \text{ and } \mathbb{P}_r, \mathbb{P}_g \ge 0$$
하지만 두 분포의 support가 겹치지 않는다면
$$P_g(x) \neq 0 \Rightarrow P_r(x) = 0 \\ P_r(x) \neq 0 \Rightarrow P_g(x) = 0$$
이기 때문에
$$\begin{align*} JS(\mathbb{P}_r || \mathbb{P}_g) &= {1 \over 2} \left ( \int_\mathcal{X} \log \left ( {P_r(x) \over (P_r(x) + P_g(x)) / 2} \right ) P_r(x) d\mu(x) + \int_\mathcal{X} \log \left ( {P_g(x) \over (P_r(x) + P_g(x)) / 2} \right ) P_g(x) d\mu(x) \right ) \\ &= {1 \over 2} \left ( \int_{Supp(P_r)} \log \left ( {P_r(x) \over P_r(x) / 2} \right ) P_r(x) d\mu(x) + \int_{Supp(P_g)} \log \left ( {P_g(x) \over P_g(x) / 2} \right ) P_g(x) d\mu(x) \right ) \\ &= {\log 2 \over 2} \left ( \int_{Supp(P_r)} P_r(x) d\mu(x) + \int_{Supp(P_g)} P_g(x) d\mu(x) \right ) \\ &= \log 2 \end{align*}$$
가 된다. 그래서 단순히 두 분포 간의 support가 겹치지 않는다는 것만으로

발산하지는 않지만 상수인 $\log 2$로 고정되어버려 "얼마나 먼지"에 대한 정보를 줄 수가 없다.
The Earth Mover (EM) Distance or Wasserstein-1
논문에서 소개하는 distance이다.
$\gamma$ : 를 $\mathbb{P}_r$, $\mathbb{P}_g$간의 joint distribution 중 하나 (= coupling)
$\Pi (\mathbb{P}_r, \mathbb{P}_g)$ : marginal이 $\mathbb{P}_r$, $\mathbb{P}_g$인 모든 joint distribution들의 집합
이라 했을 때 다음과 같이 정의된다.
$$W(\mathbb{P}_r, \mathbb{P}_g) = \displaystyle \inf_{\gamma \in \Pi (\mathbb{P}_r, \mathbb{P}_g)} \mathbb{E}_{(x, y) \sim \gamma} \left [ \lVert x - y \rVert \right ]$$
수식이 무시무시하게 생겼다. 하지만 아래의 예시를 보면서 왜 Earth-Mover라는 이름이 붙었을지 생각해본다면 금방 이해할 수 있다.
Earth-Mover란 흙을 파서 옮기는 기계라고 한다. 여기서의 의미도 크게 다르지 않다. 흙을 파서 옮기데에 드는 비용을 distance로 표현한 것이라 할 수 있겠다.
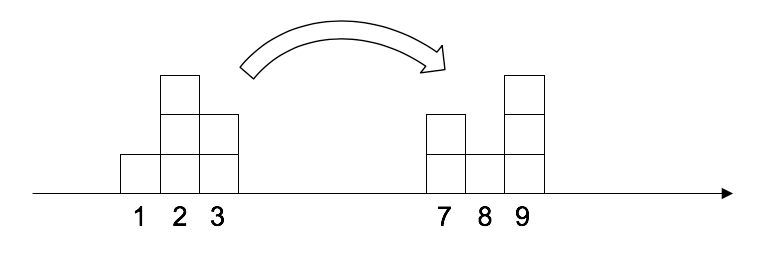
우리는 확률분포를 블록이 쌓여 있는 것으로 생각할 수 있다. 왼쪽은 $\mathbb{P}_r$, 오른쪽은 $\mathbb{P}_g$를 나타낸 것이고 왼쪽에 쌓인 8개 블록을 오른쪽 모양과 같이 옮길 것이다. 수 많은 방법 중 두 가지를 그림으로 표현해봤다.
그리고 각각의 방법의 transportation cost를 계산해볼 수 있다.
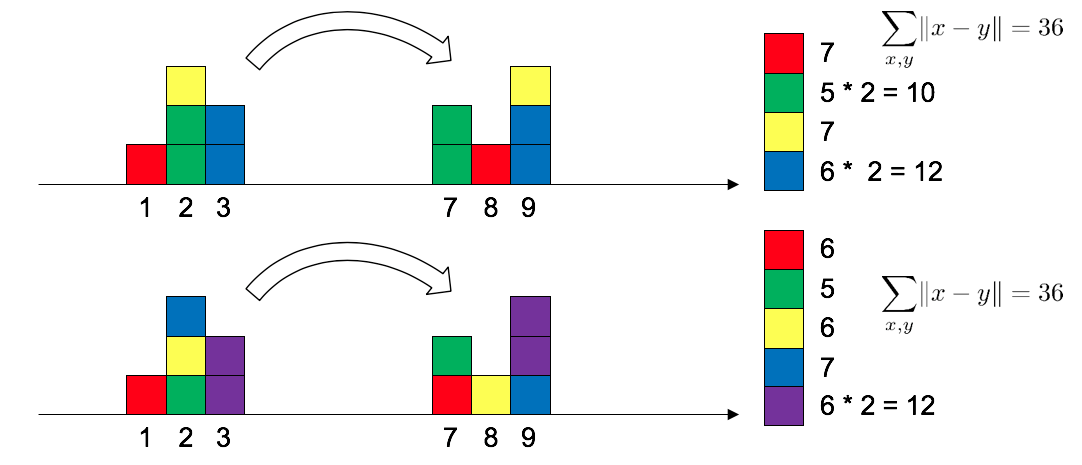
두 방법의 cost가 같은 것을 확인했다!
하지만 항상 이렇게 cost가 같은 상황만 있는 것은 아니다.

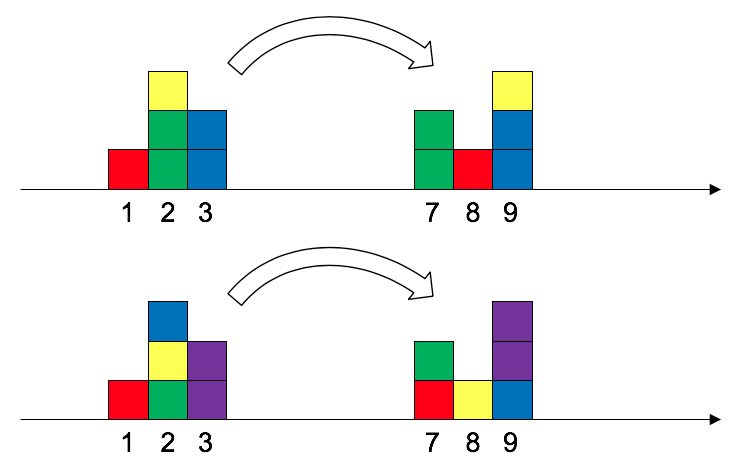
위 그림에서 검은색 블록을 회색 블록이 있는 곳으로 옮긴다고 생각해보자. 그러면 다음의 두 가지 방법이 있을 것이다.
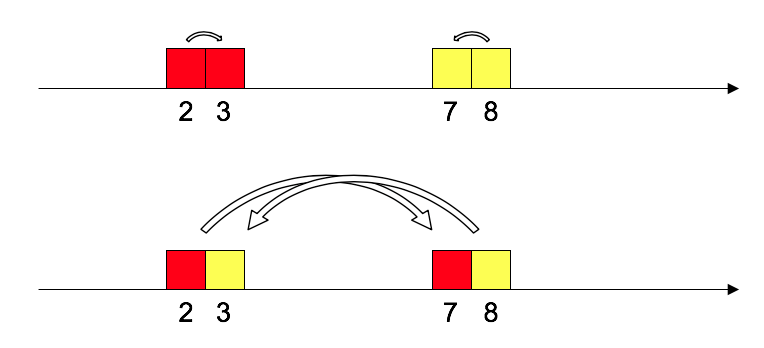
블록을 바로 옆으로 한 칸씩 옮기면 best겠지만 아래쪽처럼 멀리 옮길 수도 있겠다. 이를 transportation cost로 표현하면

$2$의 힘만 들이고도 목표한 위치로 옮길 수 있다는 것을 알 수 있다. 그리고 지금은 옮기는 방법이 두 개 밖에 없는 것이 확실하므로 cost의 최솟값이 $2$인 것도 확실하다.
사실 우리가 위에서 생각해 본 하나 하나의 plan을 joint probability distribution으로 생각할 수 있다.
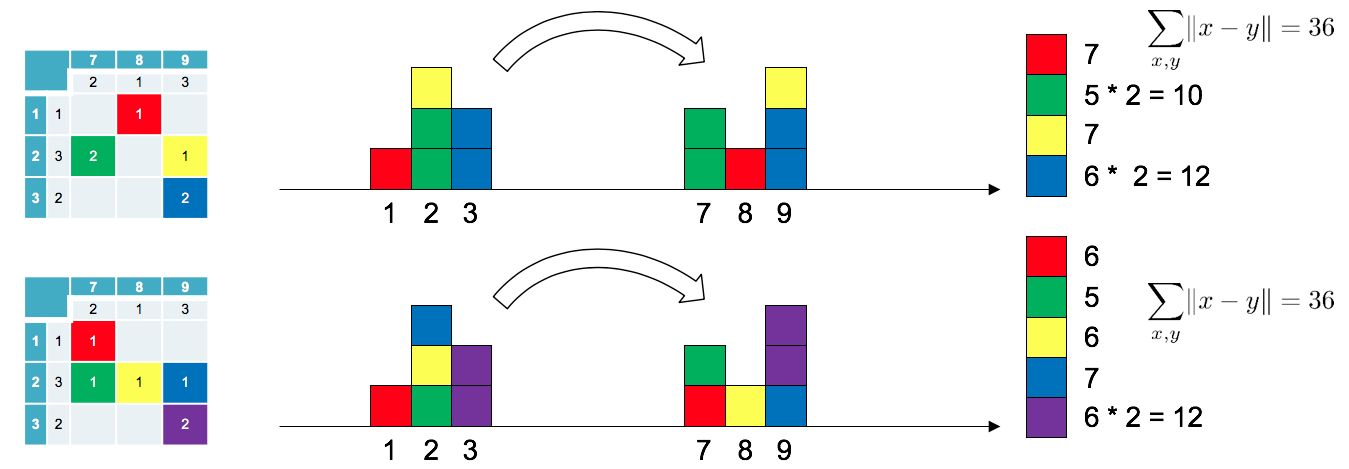
집중해서 조금만 들여다보면 무슨 말인지 이해가 될 것이다.

위의 경우도 joint probability distribution으로 생각하면

위 그림의 오른쪽 표 같이 나타낼 수 있는데 확률로 나타냈으니 이제 $W$를 계산할 수 있다.
$$W(\mathbb{P}_r, \mathbb{P}_g) = {\color{red} {\gamma_{X, Y}(2, 3)}} \times |2 - 3| + {\color{orange} {\gamma_{X, Y}(8, 7)}} \times |8 - 7| = {\color{red} {0.5}} \times 1 + {\color{orange} {0.5}} \times 1 = 1$$
이를 continuous한 경우로 확장시키면 금방 이해 될 것이다.
Example
이제 본격적으로 위에서 소개한 4개의 metric을 비교해보면서 기존의 metric들은 어떤 문제점이 있었는지 살펴보자.
이를 위해 논문에서 든 예시로

$\mathbb{P}_0$는 $x$좌표는 $0$, $y$좌표는 $0 \sim 1$ 사이의 값을 가지는 점들의 분포이고,
$\mathbb{P}_\theta$는 $x$좌표는 $\theta$, $y$좌표는 $0 \sim 1$ 사이의 값을 가지는 점들의 분포이다.
그림으로 보면 그렇게 어려운 내용은 아니다.

이제 $\theta$가 왔다 갔다 하면서 두 분포 사이의 거리를 잴건데 좋은 metric이라면 $\theta$가 0에 가까울수록 작은 값을 산출해야 한다. 하지만 $\theta \neq 0$이면 두 분포가 겹치지 않게 되고 그러면 앞에 소개한 세 metric은 의미 없는 값들을 뱉게 된다.
$$\begin{align*} &JS(\mathbb{P}_0 || \mathbb{P}_\theta) = \begin{cases} \log 2 & \text{if } \theta \neq 0 \\ 0 & \text{if } \theta = 0 \end{cases} \\ &KL(\mathbb{P}_0 || \mathbb{P}_\theta) = KL(\mathbb{P}_\theta || \mathbb{P}_0) = \begin{cases} +\infty & \text{if } \theta \neq 0 \\ 0 & \text{if } \theta = 0 \end{cases} \\ &\delta (\mathbb{P}_0, \mathbb{P}_\theta) = \begin{cases} 1 & \text{if } \theta \neq 0 \\ 0 & \text{if } \theta = 0 \end{cases} \end{align*}$$

여기서 이제 $W$를 계산해볼 수 있다.
$$W(\mathbb{P}_r, \mathbb{P}_g) = \inf_{\gamma \in \Pi (\mathbb{P}_r, \mathbb{P}_g)} \mathbb{E}_{(x, y) \sim \gamma} \left [ \lVert x - y \rVert \right ]$$
$||x - y||$의 의미는 무작위로 뽑힌 $x, y$사이의 거리이다.
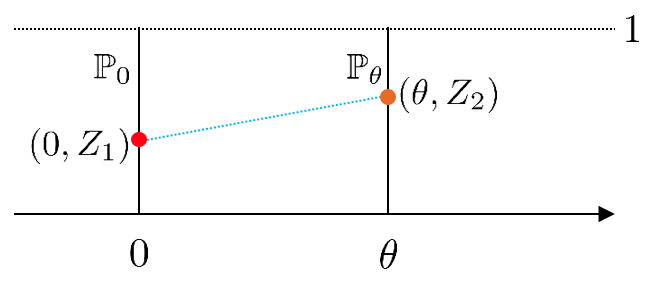
한편, 두 점 사이의 거리가 $|\theta|$보다 가까울 수는 없다.

만약 $Z_1$과 $Z_2$의 joint $\gamma$가 항상 $Z_1 = Z_2$가 되도록 sampling되게 한다면 ( $\gamma_{Z_1, Z_2} (z_1, z_2) = \delta(z_1 - z_2)$라면; $\delta$는 Dirac delta function;) 두 점 사이의 거리는 항상 $|\theta|$이고 이게 최솟값이다. 따라서
$$ \Large W(\mathbb{P}_0, \mathbb{P}_\theta) = |\theta|$$
이다.
처음으로 의미 있는 값이 나왔다! 그래프로 보면 차이점이 확연하다.

$JS$는 $\theta=0$이외에서는 constant여서 gradient가 0인 반면에 $W$는 선형이라 $\theta > 0$이면 $+$, $\theta<0$이면 $-$인 gradient를 내보낸다. 이로써 두 분포의 support가 겹치지 않아도 두 분포를 더 가깝게 유도할 수 있게 됐다.
$W$의 미분가능성과 weakness에 대한 정리와 증명은 나중에 정리하도록 하겠습니다.
Wasserstein GAN
$W$ distance가 GAN의 loss로 써먹기에 좋다는 것을 알아내긴 했지만
$$W(\mathbb{P}_r, \mathbb{P}_g) = \inf_{\gamma \in \Pi (\mathbb{P}_r, \mathbb{P}_g)} \mathbb{E}_{(x, y) \sim \gamma} \left [ \lVert x - y \rVert \right ]$$
수식의 계산이 힘들다. $(x, y) \sim \gamma$는 sampling으로 해결이 가능하지만 $\Pi$는 space가 워낙 넓어 탐색하기도 힘들고 최솟값에 대한 보장도 없을 것이다. 그래서 이 논문에서 새로운 trick을 제안한다.
Kantorovich-Rubinstein Duality Theorem 라는 것을 이용하면
$$W(\mathbb{P}_r, \mathbb{P}_g) = \sup_{||f||_L \le 1} \mathbb{E}_{x \sim \mathbb{P}_r} [f(x)] - \mathbb{E}_{x \sim \mathbb{P}_\theta} [f(x)]$$
가 된다! $||f||_L \le 1$은 $f$가 1-립쉬츠 함수(임의의 두 점 사이의 평균변화율이 1을 넘지 않는 함수)라는 뜻이다.
Kantorovich-Rubinstein Theorem에 대한 증명도 게시글로 정리해놨다. 길이가 꽤 되지만 가장 재밌게 쓴 게시글이다.
Wasserstein GAN and Kantorovich-Rubinstein Theorem 우리말 설명
Mathematics | Wasserstein GAN and Kantorovich-Rubinstein Theorem 우리말 설명
Reference 원문 : https://vincentherrmann.github.io/blog/wasserstein/ Wasserstein GAN and the Kantorovich-Rubinstein Duality Derivation of the Kantorovich-Rubinstein duality for the use in Wasserstei..
haawron.tistory.com
일단 우리는 저 정리의 도움을 받아 $f$만 알아내면 $W$값을 얻을 수 있게 됐다. 하지만 바로 알아낼 수는 없으니 변수 $w$를 추가로 사용해 $f_w$를 update하면서 근사해보자. 변수를 추가로 사용한다고 했는데 어차피 $f_w$로 $D$를 대체할 거기 때문에 정확히 말하면 변수가 늘어난 것은 아니다.
$$\max_{w \in \mathcal{W}} \mathbb{E}_{x \sim \mathbb{P}_r} [f_w(x)] - \mathbb{E}_{z \sim p(z)} [f_w(g_\theta(z))]$$
길고 긴 싸움이었지만 결국 GAN loss와 비슷한 형태를 띠게 됐다. 하지만 $||f||_L \le 1$라는 제한이 있는데 이를 어떻게 구현할지가 핵심이 되겠다.
1-립쉬츠를 구현하는 데에는 개별적인 $w$가 아니라 가능한 $w$의 집합인 $\mathcal{W}$와 관련이 있다. $\mathcal{W}$가 만든 $f_w$들을 어떤 사각형 안에 들어있다 생각해보면 이 사각형이 납작할수록 더 립쉬츠조건을 강하게 만족할 것이다. 하지만 이걸 생각하기는 너무 복잡하다. 그래서 아예 그냥 무식하게 $\mathcal{W}$를 제한해버린다!
$$\Large \mathcal{W} = [-0.01, 0.01]^d$$
update한 weight를 clipping해버리자!!는 것이다. 0.01은 실험으로 구한값이다.

머리에 물음표가 가득할 것이다. 근데 된댄다. 무식하지만 잘 작동해서 이 상태로 논문이 나오게 됐다.
Implemetation

$w$와 $\theta$를 한 번씩 update하는게 아니고 $w$를 한 번에 5번 씩 update를 한다. 기존의 GAN이면 무서워서 이렇게 못 할텐데 뒤의 실험에 이렇게 해도 안전한 이유가 나온다. 그리고 Adam을 비롯한 moment-based optimizer랑은 잘 안 맞는 모습을 보인다.
Why isn't there mode collapsing?
논문에서는 mode collapsing의 주된 원인이 판별기가 앞서 나가는 것이라고 설명하고 있다. 판별기가 학습이 앞서나가게 되면 판별기의 함수가 step function으로 수렴하게 되고 gradient vanishing이 발생하게 된다. 논문에 판별기가 앞서나가는 상황을 재현하여 실험을 해놨다. 판별기가 앞서나간다는 것을 생성기의 학습을 고정시켜놓고 판별기만 학습시킨 것으로 보았다.
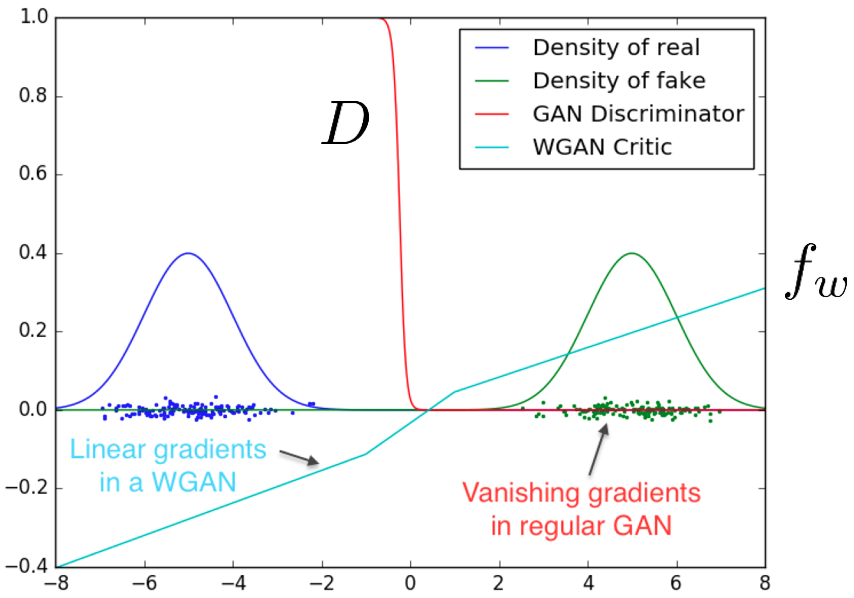
판별기는 계속 실제 데이터를 보기 때문에 생성기가 고정되어도 지속적인 학습이 가능하다. 따라서 나중엔 생성기가 생성한 fake 이미지들을 완벽히 구분할 수 있게 되어 step function형태를 띠게 된다. step function은 gradient 정보를 주지 않는다.
하지만 WGAN의 critic $f_w$같은 경우는 립쉬츠 조건 때문에 step function이 되지 않는다. Piecewise linear 형태를 띠는데 gradient 정보를 여전히 줄 수 있다.
이 실험이 시사하는 바는 판별기의 학습이 앞서나가는 것을 더이상 신경쓰지 않아도 된다는 것이다. 둘의 학습속도를 조절하기 위해 두 모델의 구조를 다르게 하고 여러가지 파라미터들을 찾는 수고를 덜 수 있게 된다.
Experiments
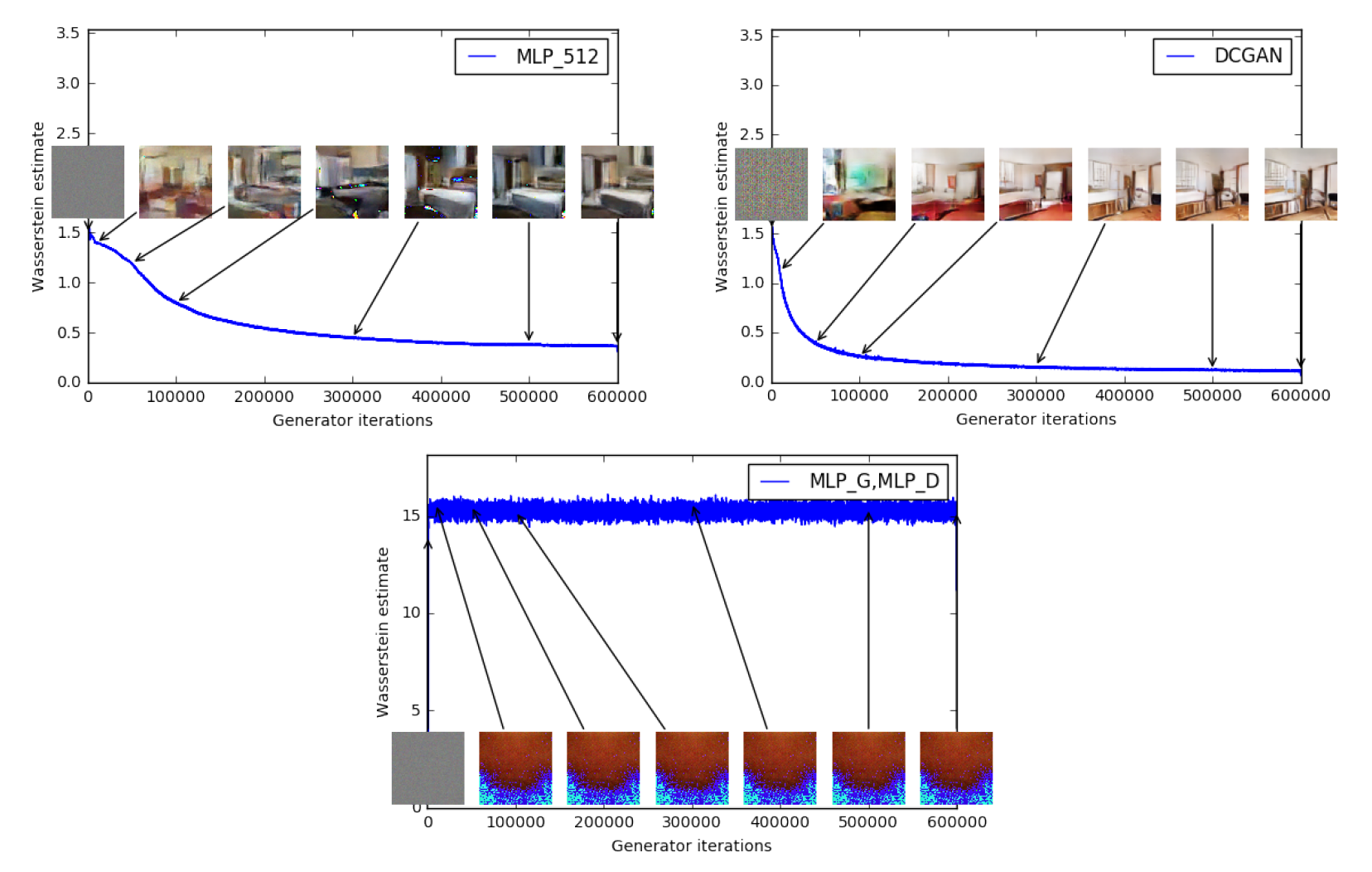

위 그림은 여러 환경에서의 Wasserstein estimate, 아래는 JSD estimate를 나타낸다. (Loss를 나타내는 것이 아니다!!)
이 실험의 초점은 각 distance가 이미지의 품질에 대한 정보를 줄 수 있냐는 것이다. 위의 W estimate 같은 경우는 이미지가 괜찮아질수록 W값이 점점 감소하는 것을 볼 수 있고 세 번째에서 망한 이미지가 나오면 W값이 줄어들지 않는 모습을 보여준다. 이를 논문에서 W가 이미지의 품질과 잘 correlate 됐다고 했다.
하지만 JSD같은 경우는 이미지가 좋아지건 말건 최적값인 $\log 2 \simeq 0.69$로 어느순간부터 고정되어 이미지 품질에 대한 정보를 주지 않는다. 게다가 세 번째 실험에서는 후반에 이미지가 조금 좋아졌지만 JSD는 오히려 올라간 모습을 보여준다.
이를 이용해 W를 GAN의 metric으로 활용하기도 한다.
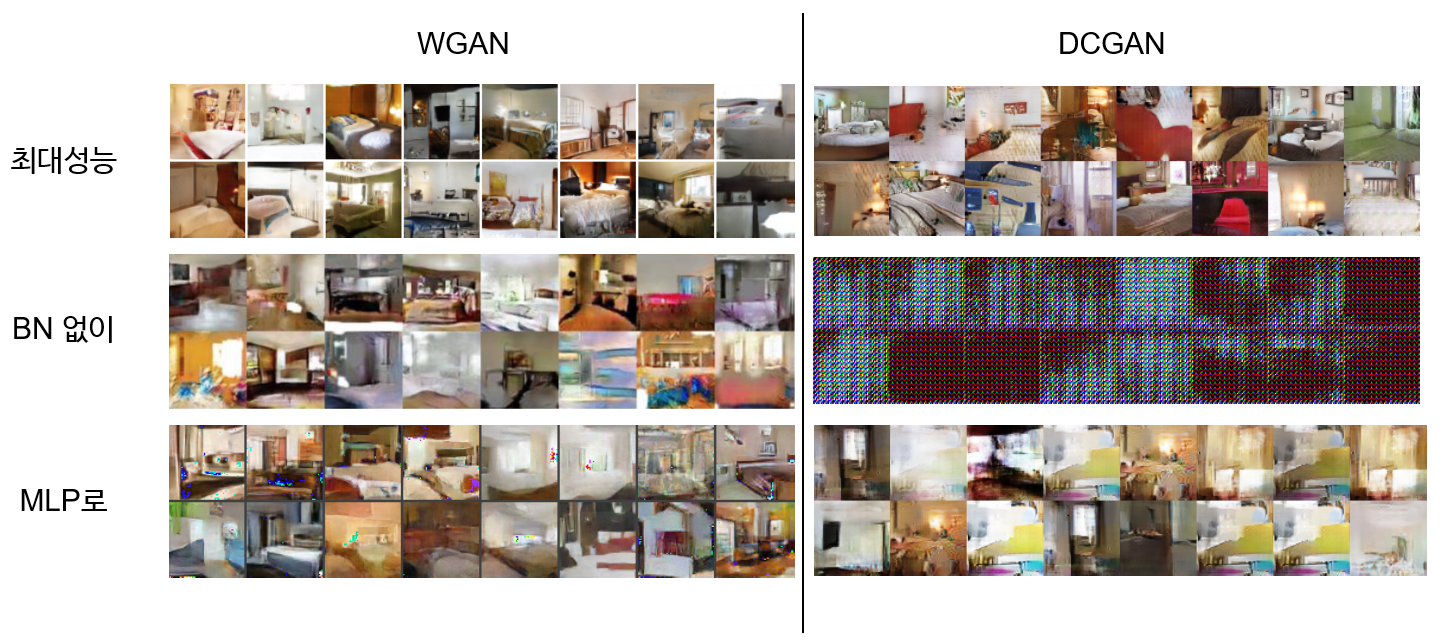
그리고 극한상황에서도 모델을 학습시켜봤다. 일반적인 상황에서도 DCGAN보다 학습이 상당히 잘 되었고 BN이 없거나 구조가 MLP인 등 극한상황에서도 어느 정도라도 학습이 이루어진 모습을 보여준다.
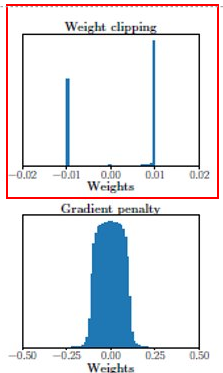
WGAN-GP (Gradient Penalty)

성능은 괜찮았지만 아직 문제가 하나 남았다.
$$\Large \mathcal{W} = [-0.01, 0.01]^d$$
바로 weight를 무식하게 clipping 해 버린 것이다. 여기에 이제 해결책을 제시한다.
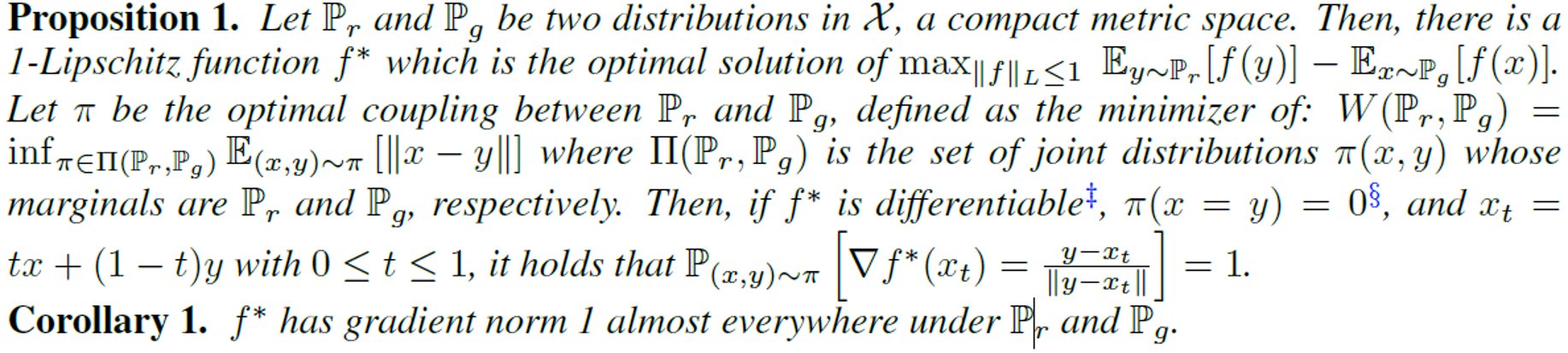
해석해보면
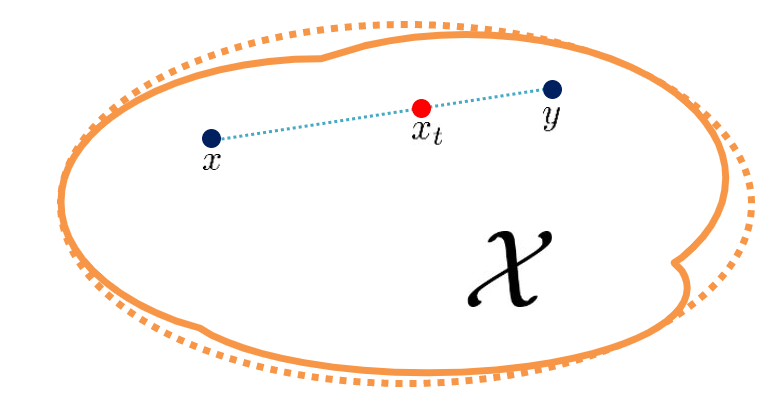
$$\arg \max_{||f||_L \le 1} \mathbb{E}_{y \sim \mathbb{P}_r} [f(y)] + \mathbb{E}_{x \sim \mathbb{P}_g} [f(x)]$$
의 최적해 $f^*$에 대해서 $x \sim \mathbb{P}_g, y \sim \mathbb{P}_r$로 sampling한 두 점의 내분점 아무곳에서나
$$\Large ||\nabla f^* (x_t)|| = 1$$
이라는 뜻이다.
Optimal $f^*$의 특성을 알게 됐으면 $f_w$가 그 특성을 갖도록 학습시키면 $f^*$에 근사할 수 있게 된다. $||\nabla f_w(x_t)|| = 1$이 되도록 critic loss에 regularizer term을 추가한다.

Implementation

아직까지도 불안정한 모델을 Adam을 사용해 더욱 안정적으로 만들어주었고, critic loss term도 해석적으로 바뀌어서 좀 더 스무스한 최적화가 가능해졌다.
Experiments

실험한 모습을 보면 WGAN-GP는 기존의 WGAN보다 극한상황에서 훨씬 더 안정적으로 학습되는 모습을 보인다. 이런 특징 때문에 WGAN-GP와 LSGAN은 현재 GAN loss의 양대산맥이 되었다. Sota 논문들을 보면 이 두 loss를 넣어 실험한다.



