Reference
GANSynth : https://openreview.net/pdf?id=H1xQVn09FX
Spherical Gaussian Distribution : https://mynameismjp.wordpress.com/2016/10/09/sg-series-part-2-spherical-gaussians-101/
Summary
나온지 얼마 안 된 따끈따끈한 논문이다. 이미지 생성에 있어 GAN은 상당히 강력한 성능을 보여주지만 음성 생성에서는 고만고만 했었다. 소리를 직접 생성하지 않고 spectrogram(이미지로 표현된 소리)을 생성하여 구현하였더니 성능이 괜찮았다고 한다.
NSynth라는 악기, 피치, 속도, 음량 등을 달리하여 한 노트씩 녹음된 정제된 데이터셋을 사용했다. 여기서 생성된 음원들을 들어볼 수 있다.
Introduction
Neural audio synthesis task에는 WaveNet같은 autoregressive model들이 있었지만 sampling 방법이 너무 구려서 sampling speed가 매우 낮았다. 하지만 성능은 좋아서 이후 이를 개선하기 위한 다른 방법들이 많이 시도되었지만 심각한 오버헤드나 과도하게 task-specific 하는 둥 효과는 미미했다. Image translation에 사용된 GAN을 그냥 그대로(straightforward) 적용해서 waveform을 생성해봤지만 이미지에서 내던 성능만큼 뛰어난 효과는 없었다.
1.1 Generating Instrument Timbers
NSynth라는 악기, 피치, 속도, 음량 등을 달리하여 한 노트씩 녹음된 정제된 데이터셋을 사용했다. 게다가 데이터들마다 labelling도 되어 있어서 conditional 하게 generation하는 데도 사용가능하다. 기존에는 이 데이터를 활용한 conditional + GAN method가 없어서 여기서 시도해 봤다고 한다.
1.2 Effective Audio Representations for GANs
이미지와 달리 소리 신호는 상당히 주기적이다. 사람은 이런 특징을 매우 잘 잡아내는데, 그래서 신호에 아주 살짝 불규칙한 노이즈가 껴도 알아챌 수 있다. 소리와 관련된 task에서는 이런 주기적인 성질까지 잘 이용하는 것이 매우 중요하다 할 수 있다.

위쪽 그림
1, 2. 우리 목소리나 악기 소리는 국소적으로 주기적인 성질을 띠는데, STFT(Short-Time Fourier Transform)나 transposed conv같은 frame-based 테크닉으로 magnitude만 sampling하면 ground truth 신호와 위상이 어긋나는 경우가 생긴다.
3. 근데 어긋나는 정도가 선형적으로 일정해서 phase를 선형적인 것처럼 보이도록 unwrap한다. Unwrap이라는 것이 별게 아니고 그냥 phase를 $[-2\pi, 0]$값을 가지도록 $2\pi$를 더해주기만 하면 된다.
4. Unwrapped phase를 시간에 대해 미분하면 Instantaneous Angular Frequency를 얻을 수 있다. 줄여서 Instantaneous Frequency라고 하기로 하자.
아래 그림
트럼펫 신호를 스펙트로그램으로 보면 아무 작업도 안 한 phase 신호는 매우 난잡하게 찍히지만 unwrap시키면 부드러워지고 IF에서는 magnitude에서 보이는 solid line들을 볼 수 있게 된다.
1.3 Contributions
다음을 포인트로 잡고 이 논문을 읽으면 되겠다.
-
Waveform이 아닌 log-magnitude spectrogram이랑 phase를 직접 GANs으로 만들었더니 좀 더 실제에 가까운 소리를 얻을 수 있었다. (이미지인 spectrogram를 예측하면 괜찮지 않을까? 했는데 진짜 괜찮음)
-
IF spectra를 예측하면 phase예측보다 더 괜찮은 소리가 나왔다.
-
저음 부분의 STFT 필터들이 겹치지 않도록 하는 것은 중요하다. 필터들은 기본음의 배음이 저음에서 많이 겹치기 때문에 저음에서 tight한 경우가 많다. Mel Frequency scale로 바꾸거나 STFT frame size를 늘리는 것으로 해결할 수 있다.
-
GANs가 autoregressive 모델 기반인 WaveNet보다 54000배 빠르게 sample을 만들 수 있다.
-
Condition에 따라 latent vector를 제한 했더니 더 부드러운 음색의 interpolation이 가능해졌다. 음색을 유지하며 피치를 바꿀 수도 있었다.
Experimental Details
2.1 Dataset
NSynth라는 데이터셋을 사용했는데 MNIST같은 매우 정제되고 정교한 데이터셋이다. 이게 이 모델의 장점이자 단점이다. 매우 task-specific한 동시에 성능은 잘 낸다. 이 부분이 이후 해결과제로 남아있다.
데이터셋을 대충 설명하자면 다음과 같다.
-
개당 4초, 1000개의 서로 다른 악기, 다양한 피치, 속도, 음질, 음량, 등등 해서 300000개가 있다.
-
16kHz로 4초니까 개당 64000차원이다.
하지만 이 중 사람 귀에 자연스럽게 들리는 32~1000Hz의 피치의 데이터만 따로 솎아내니 70479개가 남았고 이를 train/test 8:2로 나눠서 학습했다. GAN에서 왜 train/test를 나누나??? Conditional 하게 학습시키면 분류기로도 사용할 수 있다. 글 후반의 표에서 확인하자.
2.2 Architecture and Representations
Architecture
Progressive한 모델과 non-progressive한 모델 두 개를 만들었는데 non-progressive는 ACGAN(Auxiliary Classifier GAN)의 골격을 사용해 피치 정보를 condition으로 넣었다. 학습된 condition 정보를 이용해 분류기로도 사용할 수 있었다. 두 모델 다 WGAN-GP(이 논문 저자 중 한 명이 WGAN 쓴 사람이다.)와 PixelNorm을 사용했다.


Spherical Gaussian Latent Vector
그리고 이 모델의 특이한 점인데 latent vector를 일반적인 gaussian이 아닌 spherical gaussian에서 sampling했다. 이게 뭐냐면
-
기준이 될 유닛 벡터 $\mu$를 잡는다.
-
어떤 다른 유닛 벡터 $\mathbf{v}$는 $\mu$와 이루는 각의 크기 $\theta$의 cosine 값 $\cos \theta$이 있을 때 $1 - \cos \theta$는 standard gaussian을 따른다. (이래야 $\theta = 0$일 확률이 가장 높다!)
-
이런 규칙을 따르며 벡터들을 몇 개 샘플링하면 구를 이룬다.
-
그래서 Spherical Gaussian이다.
이 블로그에 정말 자세한 설명이 있다. Latent vector의 분포를 이렇게 잡으면 나중에 신기한 interpolation이 가능하다. 밑에서 확인해보자.
그 외
데이터셋으로부터 STFT를 사용해 (256, 512, 2) 스펙트로그램 이미지를 얻었다. 256은 stride, 512는 freq bins, 2는 mag와 phase를 의미한다.
$G$에서 $\tanh$를 이용하기 때문에 magnitude 이미지들의 값들에 log를 취하고 -1~1로 normalize 했다.
Baseline으로는 audio GAN계열의 sota(?)라고 할 수 있던 WaveGAN과(성능은 별로다.) autoregressive 계열의 WaveNet을 사용했다.
Model Variations
-
Phase까지 -1~1로 normalize 시킨 모델을 “phase” 모델
-
Normalize된 phase를 unwrap 시킨 것을 “IF” 모델
-
저음부분의 frequency resolution이 performance에 영향을 많이 주는 것에 영감을 받아 (128, 1024, 2) 이미지를 input으로 넣은 모델을 “+H” 모델
-
mag와 IF를 mel freq scale로 바꾼 것을 “IF - Mel” 모델
의 네 개의 성능을 비교해봤다.
Metrics
여러가지 평가 방법이 존재하는데 대충 정리하면 다음과 같다. 정확한 평가 방식은 알지 못하지만 어떤 feature를 평가하기 위한 항목인지만 정리했다.
-
Amazon Mechanical Turk (AMT) : 일정한 규칙을 가지고 사람에게 어느게 진짜인지 맞춰보라고 하는 평가방식이다. 딱히 이렇다 할 metric이 없는 GAN에게는 가장 강력한 점수이다.
-
Number of Statistically-Different Bins (NDB) : 뭔진 모르겠는데 diversity 평가
-
Inception Score (IS) : pretrained 된 classifier에 real data와 generated data를 넣어서 KLD를 계산. 값이 작을 수록 좋다.
-
Pitch Accuracy (PA) and Pitch Entropy (PE) : 같은 classifier로 KLD말고 ACC와 Entropy를 계산.
-
Fréchet Inception Distance (FID) : Inception classifier를 사용해 GMM을 학습시켜 W-2를 계산한다. 생성된 이미지의 퀄리티와 diversity를 동시에 평가 가능하다.
Results

IF-Mel + H 모델이 real data와 가장 근사함을 보인다.
Phase 모델들은 High frequency resolution (+H)을 적용해도 FID값이 높게(높을수록 안좋다.) 나오는 것을 볼 수 있다. Phase unwrapping이 효과를 본 것을 알 수 있다.

WaveNet은 신뢰도 높은 소리(high-fidelity sounds)를 만들어내지만 feedback(메아리)과 self-oscillation에 빠져 IF-GAN보다는 점수가 모자란다. WaveGAN은 성능이 많이 저조한 모습을 보인다.


WaveNet과 WaveGAN은 다양성이 부족해 peaky한 그래프를 보여주는 반면에 IF-Mel + H 모델이 생성한 데이터들은 넓게 골고루 분포되어 있다.
Qualitative Analysis
5.1 Phase Coherence

WaveformGAN이나 PhaseGAN은 phase가 불규칙적이어서 음색이 난잡한 반면 IFGAN(이 논문)은 선명한 결과를 보여준다.
5.2 Interpolation

WaveNet등의 autoregressive 계열은 상당히 국소적인 부분의 latent code만 학습해 불연속적인 interpolation을 보여준다. 게다가 두 지점 사이를 왔다갔다하는 모습도 보인다.
SynthGAN(이 논문 모델)은 모든 소리를 낼 수 있도록 spherical gaussian prior에서 학습이 됐기 때문에 interpolation이 잘 정돈된(well-aligned) 모습을 보인다. 다른 추가 작업 없이도 부드러운 interpolation이 가능하다.

5.3 Consistent Timbre Across Pitch
음색이 피치를 유지하며 변하는건 확인했고 이제 음색을 유지하며 피치를 변화하는 걸 확인할 것이다. Latent vector는 가만히 두고 피치만 바꾸면서 확인한다.
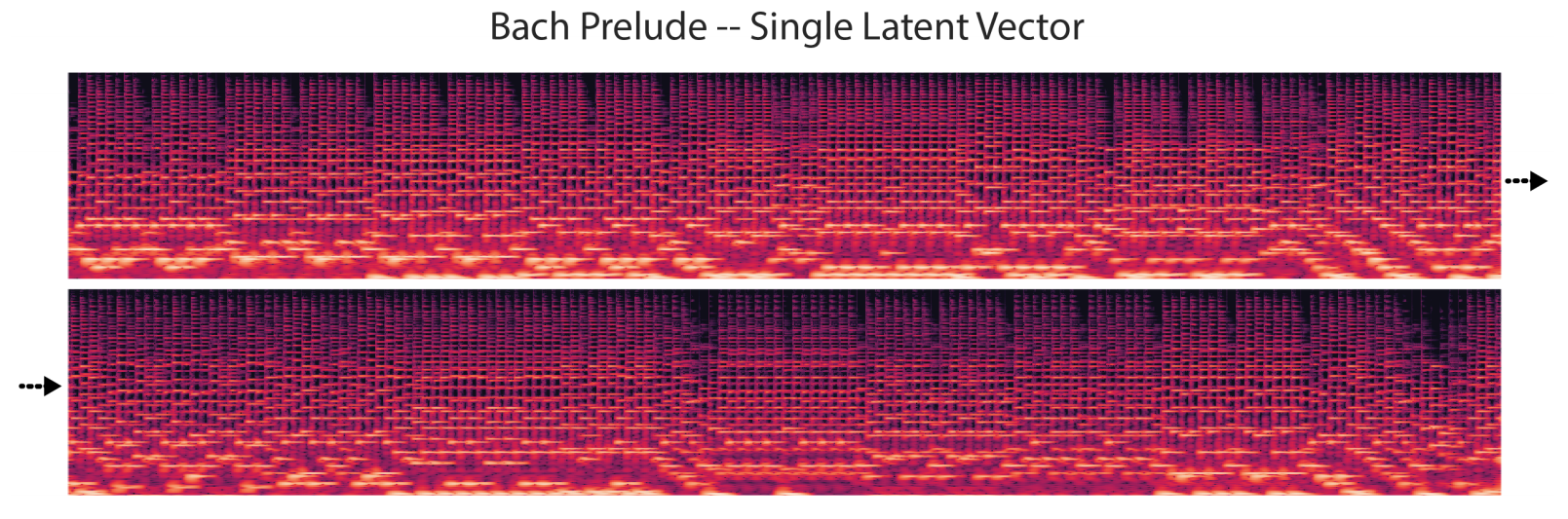
피치를 5옥타브를 varying하는 condition을 줬더니 예상대로 같은 악기 소리를 유지하며 피치가 변하는 걸 확인했다.
개인적으로 이것도 다른 모델들이랑 비교해줬으면 좋았을 거 같다고 생각한다.
Fast Generation
Autoregressive model과 달리 transposed conv를 사용하는 GAN의 장점은 GPU를 효율적으로 활용가능하다는 것이다. 그래서 Titan X로 4초짜리 음원 하나 만드는데 1077.53초(WaveNet) 걸리던 것을 20ms으로 53880배 빠르게 만들었다. 실시간 작업이 가능한 범주에 들어가게 됐다!
Conclusion
좋은 성능! 빠른 속도!
하지만 specific controlled dataset에서 진행된거라 task를 좀더 넓게 확장할 필요가 있겠다.
기존의 GAN마냥 adversarial이나 다른 좀 더 쉽고 직관적인 regression losses를 사용할 수 있게 된다면 전체 data 분포를 더 잘 잡게 될 것이다. (논문 저자가 WGAN 쓴 사람인데 왜 W-distance를 싫어하는지 모르겠다.)



