개요
$$P(B|A) = \dfrac{P(A|B)P(B)}{P(A)}$$
Bayes' Rule은 직관적이고 간단하지만 이를 통해서 전개하는 이론들은 어딘가 모르게 이해가 잘 안 되고, 눈으로는 쉬워보이는데 머리로 이해가 안 되니 스트레스로 다가온다. MLE vs. MAP vs. Bayesian이 그 예시 중 하나이다. 몇 년 째 보는 내용이지만 몇 달 안 보다가 갑자기 보면 잠깐씩 막힌다. 그동안은 막혀도 뭘 몰라서 막힌 건지도 몰라서 정리를 못했으나, 이제 머리가 좀 크고 조금 알긴 할 것 같으니 graphical하게 정리 해보겠다. 급하면 세팅이랑 그림만 봐도 될 것 같다.
Bayes' Rule
$$P(\text{Cause}|\text{Observation}) = \dfrac{P(\text{Observation}|\text{Cause})P(\text{Cause})}{P(\text{Observation})}$$
베이즈 룰을 간단하게 보고 들어가자. 어떤 사건이 발생하여 내가 그것을 관측했을 때, 원인에 대한 확률을 알아내는 공식이다. (여기서 사용하는 "원인", "결과" 같은 명명법은 학문적이지 못하다.)
- $P(\text{Observation}|\text{Cause})$: Likelihood, 사전확률, 어떠한 원인 사건이 발생했을 때, 이 관측 결과를 얻을 확률.
- $P(\text{Cause}|\text{Observation})$: Posterior, 사후확률, 관측 결과를 봤을 때, 어떤 원인 사건이 진짜 원인일 확률이다.
- $P(\text{Cause})$: Prior, 그러한 원인이 발생할 확률, 보통 사전에 알고 있는 경우가 많아서 prior라고 한다.
- $P(\text{Observation})$: Evidence, 그러한 관측이 발생할 확률, 해당 관측이 얼마나 믿을 만한 지 알려주기 때문에 evidence라고 한다.
사실 여기부터 어렵다. 간단해보이는 공식의 모든 term에 특별한 이름이 붙어있으며, 각각 이름이 무슨 의미일지 곰곰이 생각해보고자 한다면 각 실험 환경마다 최소 4번 씩 값들이 어떻게 변하는지 생각해야 된다. 변수가 4개인 셈이다. 하지만 적절한 예시 하나만 있으면 이해가 잘 된다.
실험 환경 세팅
어떤 지역의 어떤 날짜의 대기압과 강수여부가 있는 데이터를 들고 있다(shape=$[N, 2]$). 이 데이터를 기반으로 이 지역의 대기압을 기반으로 비가 올지 안 올지 맞추려고 한다. Binary classification이다. 편의상 비가 왔을 때, 안 왔을 때 데이터 수가 같다고 가정했다.
MLE: Maximum Likelihood Estimation
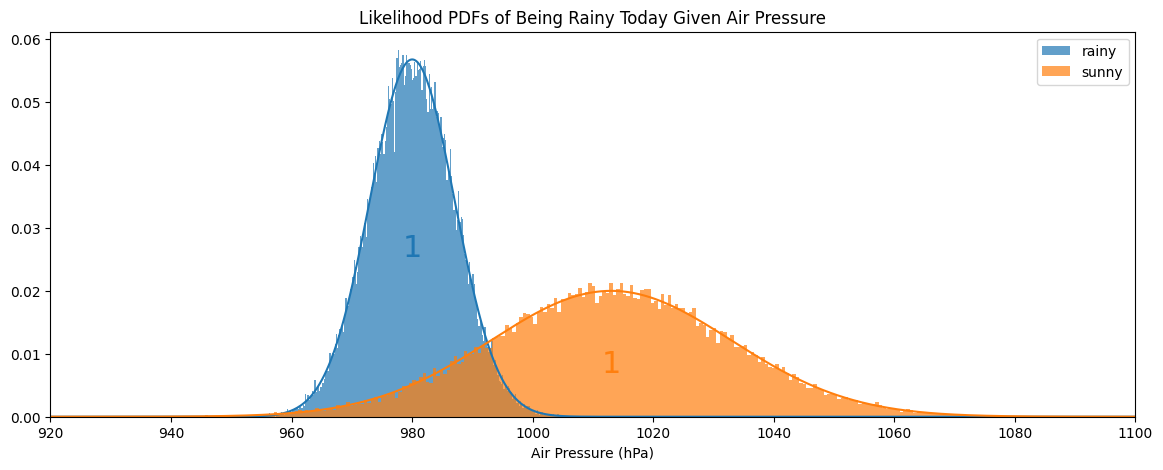
가장 간단하게 할 수 있는 건 $P(\text{Observation}|\text{Cause})$을 기반으로 예측하는 MLE이다. 원인이 강수 여부, 관측을 대기압이라고 생각한다. 갖고 있는 데이터에서, 비가 올 때 안 올 때를 나눠 각각 $\mu$, $\sigma$를 구했고, Gaussian pdf를 표기했다. 보통 이렇게 그럴 듯한 parametric pdf를 정하고 거기에 알맞은 파라미터를 구해 피팅시킨다. 가우시안은 평균과 표준편차만 알면 되기에 피팅 시킬 때 별 알고리즘이 필요없어 가장 간단하다. 오늘 대기압 $x$를 얻었다면 두 pdf의 각 값(likelihood)을 비교하여 더 큰 쪽으로 판단하는 것이 MLE이다. 예를 들어, $x=990$이라 하면 파란색이 더 크므로 오늘은 비가 온다고 예측 할 수 있겠다.
$$p(x|R) \text{ vs. } p(x|S)$$
# X: given data, shape: [N, 2]
x = np.linspace(920, 1100, 1000)
pdf_rainy = norm.pdf(x, X[:,0].mean(), X[:,0].std())
pdf_sunny = norm.pdf(x, X[:,1].mean(), X[:,1].std())MAP: Maximum A Posteriori
MAP에서는 posterior'i'라고 한다. 라틴어에서 긁어왔다고 한다.
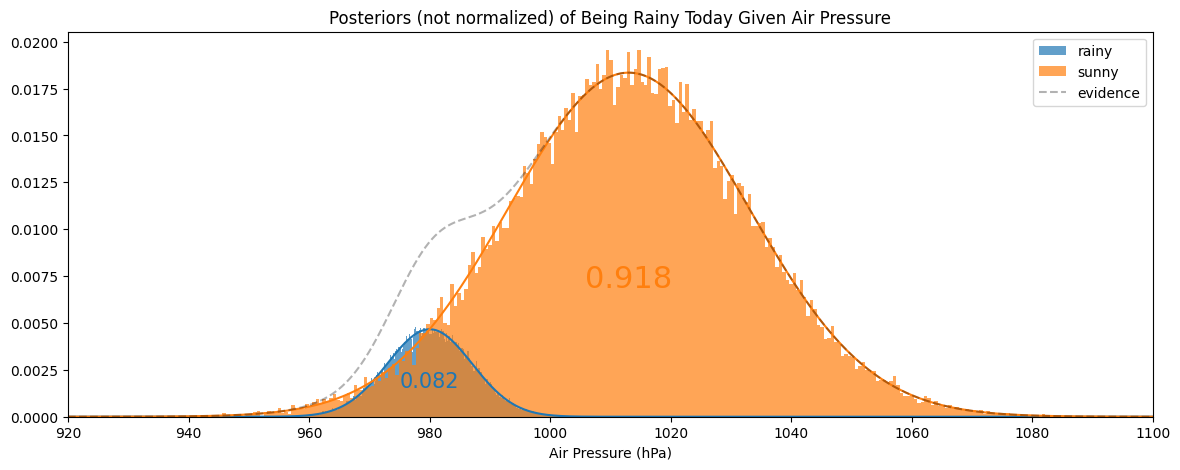
MLE에서 고려하지 않은 것이 있다. 만약 이 지역이 1년에 비가 30일밖에 안 오는 척박한 사막이라면 어떨까? (참고로 서울은 연중 100일 정도 비가 온다. 기상청) 비가 온다고 예측을 했어도 내 예측에 의심이 간다. 이럴 땐 연중에 비가 왔던/안 왔던 비율을 각 pdf에 곱해야 한다. 이 정보가 바로 prior이다.
$$p(x|R)P(R) \text{ vs. } p(x|S)P(S)$$
한 가지 재밌는 것은 각 영역의 넓이가 prior와 같다는 것이다.
이제 여기서 evidence인 $p(x)$로 나눠주면 posterior probability가 된다. 하지만,
$$p(x) = p(x, R) + p(x, S) = p(x|R)P(R) + p(x|S)P(S)$$
로 $R$, $S$에 대해 똑같을 것이기에 보통 무시한다. 따라서 위처럼 unnormalized posterior를 주로 사용하여 MAP 하게 된다. 아까와 같이 $x=990$이라면 이번엔 비가 안 온다고 예측을 하게 된다.
$$P(R|x) \varpropto p(x|R)P(R) \\ \text{ vs. } \\ P(S|x) \varpropto p(x|S)P(S)$$
여담으로 evidence가 어떻게 변하는지 그래프에 추가했다. Evidence는 $x$의 빈도수를 나타낸다. $p(x)$가 크다는 것은 데이터가 많다는 뜻이고 해당 부분은 믿을 만한 지점이라는 뜻이 되겠다.
Bayesian Estimation
그렇다면 베이지안은 뭘까? 베이지안은 값을 예측만 하는 것이 아닌, 가능한 예측들의 확률분포를 예측한다. 위 두 경우는 비가 온다/안 온다의 bool값만 예측을 했지만(binary니까), 우리는 이 예측이 얼마나 믿을 만한지 모른다. 지금 화창한데 갑자기 비가 온다고 하면 누가 믿겠는가? 따라서 내 예측이 얼마나 믿을 만한지 알려주는 불확실성에 대한 예측 또한 필요하다. 불확실성이란 정의하기 나름대로이지만 보통 (정보이론의) 엔트로피를 많이 사용하여 $[0, 1]$의 값을 가지는 양을 나타낸다.
어떤 확률분포 $p$가 주어졌을 때, 엔트로피의 정의는 다음과 같다.
$$H = -\sum_i p_i \log p_i$$
우리는 binary classification이므로
$$H = -p_0 \log p_0 - p_1 \log p_1 \\=-P(R|x) \log P(R|x) - P(S|x) \log P(S|x)$$
이 된다. 여기서 중요한 것은 $p$는 확률분포이고 합이 1이 되어야 한다는 것이다. 아까 MAP에서 evidence를 무시한다고 했는데, 그러면 더해서 1이라는 보장이 없다. 지금 위로 올라가 MAP 그림에서 아무 $x$에 세로선을 긋고 파란색+주황색이 1이 되는지 보면 된다. 되는 곳이 없을 것이다. MAP의 양변에다가 evidence를 나눠주면 합이 1이 보장되게 된다.
$$P(R|x) = \dfrac{p(x|R)P(R)}{p(x|R)P(R) + p(x|S)P(S)} \ \ \ \text{ vs.} \ \ \ p(S|x) = \dfrac{p(x|S)P(S)}{p(x|R)P(R) + p(x|S)P(S)}$$
이 둘은 $x$를 deterministic하게 간주하여 $x$에 대한 posterior function이라고 부른다. (여기서 stochastic 한 것은 $R$이거나 $S$인 것이다. (어려움)) $R$, $S$에 대해서는 distribution이다. 보통 posterior function과 posterior distribution이라는 말을 혼용해서 쓴다. 전자의 경우는 $x$의 determinedness를, 후자의 경우는 $R$, $S$의 stochasticity를 강조하는 것이다. 그림을 그리면 아래와 같다.

Stacked를 보면, 세로선을 어디서 긋든 간에 두 색의 합이 항상 1인 것을 볼 수 있다. 중요한 것은 uncertainty이다. 둘 중 어느 것을 골라야 할지 애매하다면 큰 값을, 확실하다면 작을 값을 보인다. 내 예측이 얼마나 uncertain 한가를 알기 위해 베이지안을 하고 posterior distribution을 구한 것이다.
이제 예측은 "비가 온다/안 온다"가 아닌 "비가 올 확률이 30%, 안 올 확률이 70%"와 같이 예측하게 된다.
'수학' 카테고리의 다른 글
| Mathematics | Fourier Analysis | Basic Properties of Fourier Series (2) | 2021.08.14 |
|---|---|
| Mathematics | Information Theory | Entropy, Information (0) | 2021.08.13 |
| Mathematics | Wasserstein GAN and Kantorovich-Rubinstein Theorem 우리말 설명 (3) | 2019.05.04 |
| Mathematics | 왜 하필 Borel Set일까? (1) | 2019.03.21 |



