그래서 Mamba가 무엇인가? 왜 이렇게 유명한가?

맘바는 time-varying state-space model (SSMs) + hardware-aware state materialization이다.
최근 LLM의 작동 방식은 다음 단어 맞히기이다. 사용자의 질문 + 자신이 지금까지 했던 답변을 보고 제일 그럴듯한 다음 단어를 예측한다. Auto(스스로)-regressive(참고) 하다고 한다. 한 문장을 생성하기 위해 단어 개수만큼의 forward pass가 요구된다. 초대형 트랜스포머인 LLM은 단 한 번의 forward pass도 엄청난 양의 연산량을 요구한다. 지구의 엔트로피를 올리는 주범이 된 지 오래다.
LLM의 연산량을 줄이려는 시도는 매우 많았다. 두 가지로 귀결된다. 하나는 auto-regressive를 없애는 종류, 하나는 트랜스포머를 대체하는 종류이다. 맘바는 전자이다. 완전히 non-auto-regressive는 아니지만 적절히 compensate 해서 두 마리 토끼를 잡았다.

기존 open-source LLM 모델 대비 비슷하거나 적은 파라미터 수로 큰 성능 향상을 보여줬다. 특히 파라미터가 적은 쪽, LAMBADA 같이 long-term dependency를 요구하는 곳에서 성능 향상이 매우 컸다.
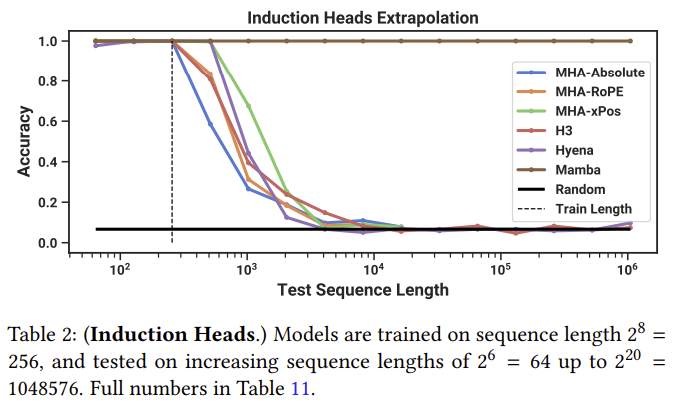
그리고 맘바는 엄청난 extrapolate 성능을 보여준다. 짧은 길이의 데이터만으로 학습이 됐어도 1000배 가까이 되는 데이터에서도 성능을 유지한다.

라고 주장했다.
앞으로 + 목표
맘바의 근원은 HiPPO라는 long-term 시퀀스 모델링 방법이다. LSTM, GRU 등의 RNN 정도로 생각하면 된다. 소리 등의 긴 1차원 신호를 모델링 할 때는 장기 기억을 저장 및 복원하는 것이 핵심이다. 다항식은 계수만 알면 완전 복원이 되기 때문에 전체적 그래프의 모습을 계수 몇 개로 효율적으로 압축해 저장하고 완전히 복원할 수 있다. 기억은 실시간이기에 장기 기억 모델링을 실시간 다항 회귀 문제로 다뤘다. "실시간" 조건 때문에 자연스럽게 SSM이 나오게 된 꼴이다. Long-term 시퀀스 모델링 성능은 물론, 기존 RNN 계열의 약점이던 인풋 속도 변형에도 robust 한 모습을 보여줬다. 약간의 보정만 거쳐주면 100Hz 모델이 200Hz 모델로도 성능 저하가 거의 없이 작동한다.
우리는 맘바에서 SSM이 무엇을 의미하는지, 왜 강력한지, 맘바의 행렬들 $\bar{A}, \bar{B}, \bar{C}$에 들어간 조건들은 무엇인지, 왜 $A$의 초기화 방법에 따라 (조금이지만) 성능 차이가 나는지 알아볼 것이다.
해당 초기화 방법은 HiPPO에서 발견되어 이어져왔고, S4에서 조건을 몇 개 버려 속도를 크게 개선하며 유명세를 탔다.


하지만, HiPPO건 S4건 논문을 처음 보면 당황스럽다. 차근차근 이해해보는 것이 이 글타래의 목표이다.
다음 순서로 진행될 예정이다.
- [포스트1] [포스트2] [arXiv] HiPPO
[포스트] [arXiv] LSSL- [포스트] [arXiv] S4
- [포스트] [arXiv] Mamba
- [포스트] [arXiv] Mamba-2
- (기회가 된다면) Mamba descendants work 들...
사실 맘바에서는 이전 work들에서 주장한 수학적 조건들이 거의 무의미해졌기에 필수는 아니다. 하지만 우리는 더 알고싶다!
'AIML' 카테고리의 다른 글
| [Mamba 이해하기 1-2] HiPPO 깊게 알아보기 (0) | 2024.09.18 |
|---|---|
| [Mamba 이해하기 1-1] HiPPO의 A 행렬의 중요성 | HiPPO: Recurrent Memory with Optimal Polynomial Projections, Gu et al., NeurIPS 2020 (0) | 2024.09.03 |

