VideoBERT: A Joint Model for Video and Language Representation Learning
Chen Sun, Austin Myers, Carl Vondrick, Kevin Murphy, and Cordelia Schmid
Google Research
ICCV 2019 (잠실 코엑스!!)
2024년 2월 기준 인용 수 무려 1200회
VideoBERT: A Joint Model for Video and Language Representation Learning
Self-supervised learning has become increasingly important to leverage the abundance of unlabeled data available on platforms like YouTube. Whereas most existing approaches learn low-level representations, we propose a joint visual-linguistic model to lear
arxiv.org
요약
- 비디오는 레이블링이 어렵기 때문에 레이블이 없는 데이터를 최대한 활용하는 게 중요하다.
- 그 방법 중 하나가 SSL(self-supervised learning)인데, 당시 비디오 SSL은 텍스처 등의 저레벨 표현(representation)만 학습하는 문제가 있었다.
- 영상이 분 단위로 길어지면 고레벨 표현도 배워야 downstream 문제들을 잘 풀 수 있다.
- 영상의 오디오로부터 캡션을 얻을 수 있을 때, 이 둘을 BERT로 video-text joint 모델링 하는 법을 제시한다.
- Text-only 모델인 BERT를 비디오에 적용할 때 토큰화 등 여러 엔지니어링이 필요한데 이들이 핵심인 것 같다.
내 의견
- 매우 잘 쓴 논문 같다. 구조가 잘 잡혀있어서 읽기가 쉽다. 역시 구글.
- CLIP(Radford et al., ICML 2021) 이전 원시적인 멀티모달 모델링 방법 중 하나이다.
- 공식 코드가 없다. 그도 그럴 것이 사용한 데이터셋이 내부에서 만든 것이라 재구현이 불가능하다. Validation을 무려 176 시간짜리 YouCook2에서 한다. (웨이트라도 주지...)
- 어떤 네덜란드 사람이 짜놓은 코드가 있긴 하다. 코드가 깔끔하긴 하나 텐서플로우이다. 리드미가 네덜란드어라 학습을 뭘로 시켰는지는 모르겠다.
개요
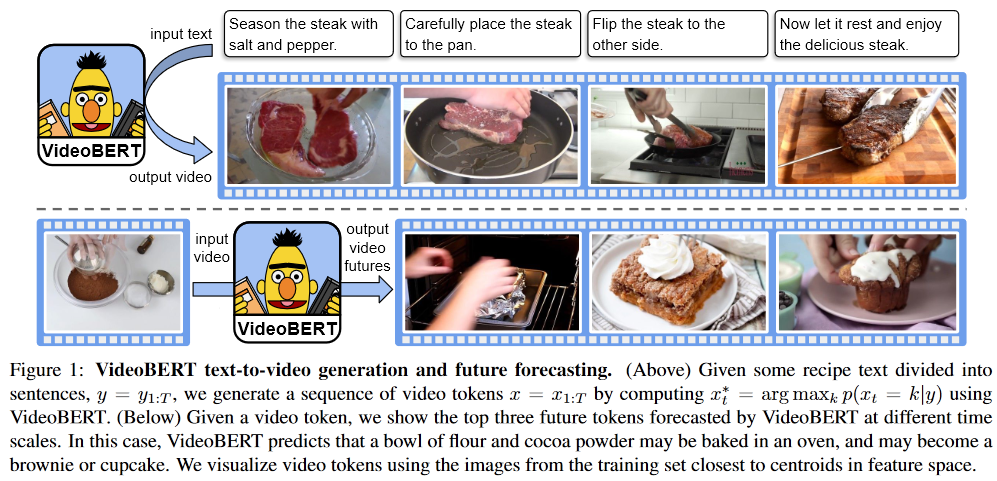
Long-term Video Understanding은 왜 필요한가? 그냥 Short-term 모델인 InternVideo 쓰면 안 되나?
유튜브 쇼츠는 1분 미만이지만 비디오 이해에서는 길이가 1분만 넘어가도 long이라고 부른다. 간단한 액션 맞추기 등은 30초 미만의 비디오가 input으로 들어가는 InternVideo 등의 잘 되는 short-term 모델을 windowing* 해서 풀 수도 있지만, 어차피 고기 구우면 기름 나오는데 왜 굳이 오일을 붓는가? 집에 맛술이 없으면 안 넣어도 되나? 등의 복잡한 질문을 해결하려면 결국 global context의 이해가 필요하다. 물론 여기선 액션 맞추기, 캡셔닝 등의 상대적으로 단순한 task만 하지만 긴 비디오 이해는 이런 의미를 갖는다.
*긴 비디오를 $T$ 초 단위인 subclip으로 잘라서 short-term 모델에 feed. 보통 1 ~ 10초로 자른다.
기존엔 어떤 시도가 있었나?
비디오 SSL과 멀티모달 방법으로 나눠서 생각해야 한다. 참고로 논문에선 멀티모달 대신 cross-modal이라는 말을 썼다. 모드를 2개만 썼다는 것을 강조하려는 목적 같지만 현재는 별 구분 없이 쓰니, 멀티모달로 통일한다.
- 비디오 SSL: VAE, GAN 등의 implicit latent 모델링 방법 등을 주로 언급했다. BERT 기반 모델링은 이러한 확률 모델이 필요가 없다는 걸 차이점으로 꼽는다.
- 멀티모달: 비디오 대부분은 오디오가 딸려있다. 특히 여기서 다루고 있는 instructional 비디오들은 음성으로 상황을 설명해준다. 그리고 음성과 영상이 temporally aligned 되어있기에 강력한 supervision으로 사용할 수 있다. 여기선 직접적인 음성 대신 유튜브 ASR(Automatic Speech Recognition; 받아쓰기) API를 사용해 얻은 캡션을 사용했다고 한다.
모델
VideoBERT는 비디오, 텍스트 시퀀스를 단순히 concat해서 BERT로 모델링 한 모델이다. 하지만 BERT의 pre-training 기법들을 비디오 멀티모달 영역으로 끌고 오기 위해 여러 가지 엔지니어링 방법을 찾아냈다.
BERT 잠깐 설명
Text-only 모델이고, 보통 GPT와 함께 언급된다. GPT는 인풋 시퀀스를 모델링 후 답변을 토큰 단위로 만들어내는 auto-regressive & decoder 모델이고, BERT는 인풋 시퀀스를 잘 이해하는 것 자체가 목적인 bi-directional & encoder 모델이다. 시퀀스를 잘 이해하는 인코더를 만들어 downstream에 backbone으로 적용하는 것이 목표이다.
인풋 시퀀스를 잘 이해하기 위헤서 두 가지 pre-training 기법을 제시한다.
- MLM(Masked Language Modeling): 인풋 토큰 중 몇 개를 마스크 토큰 `[MASK]`로 대체하고 해당 부분 아웃풋 피처를 MLP에 통과시켜서 그 부분이 무슨 토큰이었을 지 맞추게 한다. 오토인코더랑은 다르다. 오토인코더는 아예 피처를 MSE 등으로 recon 시키는 regression 방법이고, 이건 내가 알고 있는 토큰 중 무슨 토큰인지 맞추는 classification 문제이다.
- NSP(Next Sequence Prediction): 임의의 두 문장을 별도의 `[SEP]`이라는 separator를 섞어 concat 하여 연속된 문장인지 랜덤한 문장인지 맞추게 한다. 기술적으로는 `[CLS] s01 ... s0N [SEP] s11 ... s1M` 과 같이 문장 두 개를 엮은 후, 끄트머리에 `[CLS]` 를 인풋으로 받는 MLP를 달아 binary classification 시킨다.
딥러닝에서 MLM, NSP 하면 거의 BERT를 레퍼런스 하는 것이다.
VideoBERT = Concat + BERT
간단해보이는 아이디어이지만 MLM, NSP을 적용하기 위해 머리를 살짝 굴려야 한다.
비디오 피처 뽑기
비디오는 피처 뽑는 것부터 전쟁이다. 보통 short-term video model을 windowing 해서 뽑는다. 인풋 프레임 개수, 프레임 rate, window 오버랩 등을 정해야 한다. 20 FPS에 30 프레임, 오버랩은 없게 설정해서 S3D로 뽑았다고 한다.
비디오 토큰화(Tokenization)
BERT는 토큰이라는 discrete 피처를 사용한다. `'chair'`는 $v_\text{chair}$에 `'television'`은 $v_\text{television}$에 매핑해야 한다. 하지만 비디오는 다르다. 같은 계란 섞기 영상이어도 나오는 벡터는 천차만별이다. (여기선 backbone으로 S3D를 쓴다.) 이러한 continuous 벡터들을 discrete 하게 매핑하기 위해 k-means를 사용한다. 돌려서 나온 centroid 중 가장 가까운 것에 할당하는 식으로 해결한다. 하지만 k-means는 매우 비싼 알고리즘이다. Minibatch hierarchical k-means라는 것을 사용해 계산을 현실적으로 줄였다. 4레벨에 $k=12$를 줘서 총 $12^4 = 20736$개의 클러스터가 나온다고 한다.
Kinetics pretrained 된 S3D feature를 다 뽑아 MH k-means를 돌려서 나온 centroid들로 토큰들을 초기화시켜놓고 freeze 해서 썼다고 한다.
MLM & MVM(?)
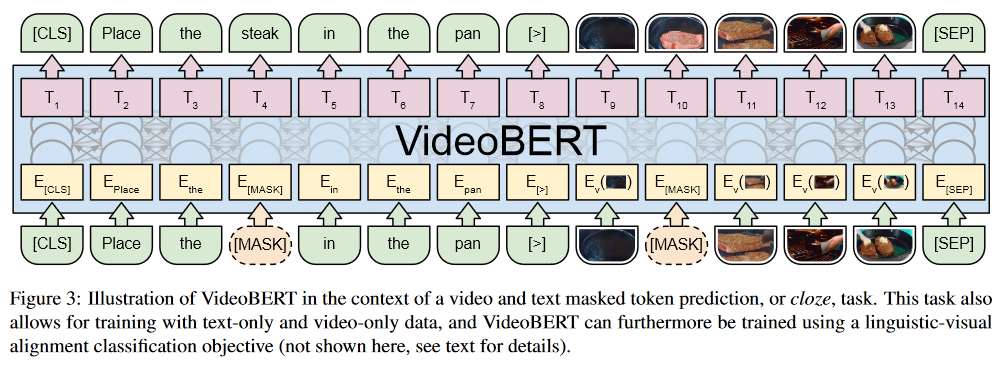
Masked 모델링 방법을 캡션, 비디오 둘에 다 적용할 수 있다. 그리고 섞어서도 할 수 있다. 여기선 셋 다 사용했다고 하는데 코드가 없어서 정확히 뭐가 인풋이고 뭐가 아웃풋인지는 모르겠다.
NSP 대신에 Temporal Alignment Prediction(?)
NSP를 비디오에 바로 적용하기 애매했다고 한다. 내 생각엔 비디오는 시각적으로 매우 연속적이기에 다음 클립 맞추기는 너무 쉬워서 그런 것 같다. 그래서 그냥 주어진 캡션과 영상이 같은 시간에서 뽑힌 건지 binary classification 했다고 한다.
여기서 또 문제가 있다고 한다. 저자들은 영상과 캡션 간에 시간 차이가 조금 있었다고 한다. 요리 instructional 비디오 같은 경우는 재료를 식탁에 올려놓고 한 바닥 설명 후 요리를 시작한다. 캡션과 영상이 살짝씩 안 맞는다. 그래서 해당 영상 내 임의의 이웃한 캡션들을 concat해 긴 문장으로 만들어 사용했다고 한다. Temporal alignment는 어차피 noisy하니까 대충만 맞추는 걸 목표로 삼은 것 같다.
데이터셋
말도 안 되게 큰 데이터셋을 사용한다. 논문 출처가 구글 리서치이다. 유튜브 API를 사용해 토픽이 "cooking", "recipe"이고 15분 이하인 영상 30만 개를 모았다고 한다. 무려 2만 3천 시간짜리이다. 초대형 데이터셋 취급 받는 Ego4D가 3000시간이다. 게다가 validation을 무려 176시간짜리 YouCook2에서 한다.
역시 unsupervised를 SSL로 풀려면 데이터가 커야 한다.
YouCook2는 액션 레이블 없이 캡션만 제공하는데, validation을 위해 저자들이 자체적으로 레이블을 추출했다. Section 4.4에 써있다.
결과

`“now let me show you how to [MASK] the [MASK],”`에서 mask 부분에 해당하는 토큰을 예측하는 것으로 동사와 명사를 zero-shot 행동 분류를 할 수 있다.
- YouCook2 레이블 가지고 S3D(frozen) + 시간 축에 average pooling + Linear 학습
- 캡션만 가지고 학습한 BERT 가지고 캡션만으로 valid
- 멀티모달로 학습한 VideoBERT 가지고 캡션만으로 valid
- 멀티모달로 학습한 VideoBERT 가지고 영상, 캡션 둘 다로 valid
- 2 vs. 3: 비디오 분류 문제에서 캡션을 사용하는 경우, 비디오를 사용하지 않고도 문제를 푸는 경우가 많다. 해당 부분을 확인하는 실험이다.
- 1 vs. 4: Zero-shot으로 비슷한 성능을 달성했다. VideoBERT는 open-vocab 모델이나 다름 없기 때문에 top-1 말고 top-5를 봐달라고 한다.

데이터셋의 힘을 보여주는 실험이다. 비지도를 SSL로 풀려면 데이터셋이 비정상적으로 커야 한다.

S3D captioning baseline에 VideoBERT feature를 뽑아 concat 하는 식으로 인풋을 구성하고 captioning 모델을 fine-tune 시켰다고 한다. Captioning 쪽은 성능이 애매한 것 같다. Captioning 쪽은 인사이트가 없어 판단이 안 선다.
결론
좀 더 복잡한 task에서도 활용해보면 어떨까 하는데 공식 코드도 없고 데이터셋도 접근성이 없어서 정말 아쉽다.
데이터셋이 적은 supervised에서 long-term aggregator로 사용하면 어떨까 고민 중인데 SSL 자체가 데이터셋이 커야 의미가 있는지라 supervised에서 auxiliary 하게 사용해도 될 지 고민중이다.
오히려 여기서 사용한 MH k-means를 돌려 centroid로 할당하는 방식은 확실히 유효할 것 같다.