
개요
이 글에서는 mmaction2는 어떻게 돌아가는지 config의 각 옵션은 무엇을 뜻하는지 알아볼 것이다.
mmaction2는 config 파일이 절반이다. Config 파일만 이해하면 마음대로 튜닝할 수 있다. 다만 처음 진입장벽이 살짝 있는 편이다. mmaction2에서 제공하는 docs를 기반으로 알아보자. Docs에는 굉장히 compact하게 써놨다. 주석을
전체 Config 파일
아래는 docs(2022.08.20 기준)에서 제공하는 TSN[Wang et al., T.PAMI 2018] 모델의 config 파일이다. 한 부분씩 뜯어보면서 알아보자.
해당 글은 RGB 기반 action recognition 모델들만 다룰 것이다. Skeleton 기반 모델이나 detection, localization 등 다른 task를 위한 옵션들이 더 있으나, 숙련도가 낮아 이 글에는 담지 않을 것이다.
모든 분야가 그렇듯, 이론을 처음부터 다 완벽히 이해하는 것은 불가능하다. 한 30% 정도 이해했다는 생각이 들면 과감하게 다음으로 넘어가서 코드를 돌려보고 오면 이해가 더 빠르다.
# model settings
model = dict( # Config of the model
type='Recognizer2D', # Type of the recognizer
backbone=dict( # Dict for backbone
type='ResNet', # Name of the backbone
pretrained='torchvision://resnet50', # The url/site of the pretrained model
depth=50, # Depth of ResNet model
norm_eval=False), # Whether to set BN layers to eval mode when training
cls_head=dict( # Dict for classification head
type='TSNHead', # Name of classification head
num_classes=400, # Number of classes to be classified.
in_channels=2048, # The input channels of classification head.
spatial_type='avg', # Type of pooling in spatial dimension
consensus=dict(type='AvgConsensus', dim=1), # Config of consensus module
dropout_ratio=0.4, # Probability in dropout layer
init_std=0.01), # Std value for linear layer initiation
# model training and testing settings
train_cfg=None, # Config of training hyperparameters for TSN
test_cfg=dict(average_clips=None)) # Config for testing hyperparameters for TSN.
# dataset settings
dataset_type = 'RawframeDataset' # Type of dataset for training, validation and testing
data_root = 'data/kinetics400/rawframes_train/' # Root path to data for training
data_root_val = 'data/kinetics400/rawframes_val/' # Root path to data for validation and testing
ann_file_train = 'data/kinetics400/kinetics400_train_list_rawframes.txt' # Path to the annotation file for training
ann_file_val = 'data/kinetics400/kinetics400_val_list_rawframes.txt' # Path to the annotation file for validation
ann_file_test = 'data/kinetics400/kinetics400_val_list_rawframes.txt' # Path to the annotation file for testing
img_norm_cfg = dict( # Config of image normalization used in data pipeline
mean=[123.675, 116.28, 103.53], # Mean values of different channels to normalize
std=[58.395, 57.12, 57.375], # Std values of different channels to normalize
to_bgr=False) # Whether to convert channels from RGB to BGR
train_pipeline = [ # List of training pipeline steps
dict( # Config of SampleFrames
type='SampleFrames', # Sample frames pipeline, sampling frames from video
clip_len=1, # Frames of each sampled output clip
frame_interval=1, # Temporal interval of adjacent sampled frames
num_clips=3), # Number of clips to be sampled
dict( # Config of RawFrameDecode
type='RawFrameDecode'), # Load and decode Frames pipeline, picking raw frames with given indices
dict( # Config of Resize
type='Resize', # Resize pipeline
scale=(-1, 256)), # The scale to resize images
dict( # Config of MultiScaleCrop
type='MultiScaleCrop', # Multi scale crop pipeline, cropping images with a list of randomly selected scales
input_size=224, # Input size of the network
scales=(1, 0.875, 0.75, 0.66), # Scales of width and height to be selected
random_crop=False, # Whether to randomly sample cropping bbox
max_wh_scale_gap=1), # Maximum gap of w and h scale levels
dict( # Config of Resize
type='Resize', # Resize pipeline
scale=(224, 224), # The scale to resize images
keep_ratio=False), # Whether to resize with changing the aspect ratio
dict( # Config of Flip
type='Flip', # Flip Pipeline
flip_ratio=0.5), # Probability of implementing flip
dict( # Config of Normalize
type='Normalize', # Normalize pipeline
**img_norm_cfg), # Config of image normalization
dict( # Config of FormatShape
type='FormatShape', # Format shape pipeline, Format final image shape to the given input_format
input_format='NCHW'), # Final image shape format
dict( # Config of Collect
type='Collect', # Collect pipeline that decides which keys in the data should be passed to the recognizer
keys=['imgs', 'label'], # Keys of input
meta_keys=[]), # Meta keys of input
dict( # Config of ToTensor
type='ToTensor', # Convert other types to tensor type pipeline
keys=['imgs', 'label']) # Keys to be converted from image to tensor
]
val_pipeline = [ # List of validation pipeline steps
dict( # Config of SampleFrames
type='SampleFrames', # Sample frames pipeline, sampling frames from video
clip_len=1, # Frames of each sampled output clip
frame_interval=1, # Temporal interval of adjacent sampled frames
num_clips=3, # Number of clips to be sampled
test_mode=True), # Whether to set test mode in sampling
dict( # Config of RawFrameDecode
type='RawFrameDecode'), # Load and decode Frames pipeline, picking raw frames with given indices
dict( # Config of Resize
type='Resize', # Resize pipeline
scale=(-1, 256)), # The scale to resize images
dict( # Config of CenterCrop
type='CenterCrop', # Center crop pipeline, cropping the center area from images
crop_size=224), # The size to crop images
dict( # Config of Flip
type='Flip', # Flip pipeline
flip_ratio=0), # Probability of implementing flip
dict( # Config of Normalize
type='Normalize', # Normalize pipeline
**img_norm_cfg), # Config of image normalization
dict( # Config of FormatShape
type='FormatShape', # Format shape pipeline, Format final image shape to the given input_format
input_format='NCHW'), # Final image shape format
dict( # Config of Collect
type='Collect', # Collect pipeline that decides which keys in the data should be passed to the recognizer
keys=['imgs', 'label'], # Keys of input
meta_keys=[]), # Meta keys of input
dict( # Config of ToTensor
type='ToTensor', # Convert other types to tensor type pipeline
keys=['imgs']) # Keys to be converted from image to tensor
]
test_pipeline = [ # List of testing pipeline steps
dict( # Config of SampleFrames
type='SampleFrames', # Sample frames pipeline, sampling frames from video
clip_len=1, # Frames of each sampled output clip
frame_interval=1, # Temporal interval of adjacent sampled frames
num_clips=25, # Number of clips to be sampled
test_mode=True), # Whether to set test mode in sampling
dict( # Config of RawFrameDecode
type='RawFrameDecode'), # Load and decode Frames pipeline, picking raw frames with given indices
dict( # Config of Resize
type='Resize', # Resize pipeline
scale=(-1, 256)), # The scale to resize images
dict( # Config of TenCrop
type='TenCrop', # Ten crop pipeline, cropping ten area from images
crop_size=224), # The size to crop images
dict( # Config of Flip
type='Flip', # Flip pipeline
flip_ratio=0), # Probability of implementing flip
dict( # Config of Normalize
type='Normalize', # Normalize pipeline
**img_norm_cfg), # Config of image normalization
dict( # Config of FormatShape
type='FormatShape', # Format shape pipeline, Format final image shape to the given input_format
input_format='NCHW'), # Final image shape format
dict( # Config of Collect
type='Collect', # Collect pipeline that decides which keys in the data should be passed to the recognizer
keys=['imgs', 'label'], # Keys of input
meta_keys=[]), # Meta keys of input
dict( # Config of ToTensor
type='ToTensor', # Convert other types to tensor type pipeline
keys=['imgs']) # Keys to be converted from image to tensor
]
data = dict( # Config of data
videos_per_gpu=32, # Batch size of each single GPU
workers_per_gpu=2, # Workers to pre-fetch data for each single GPU
train_dataloader=dict( # Additional config of train dataloader
drop_last=True), # Whether to drop out the last batch of data in training
val_dataloader=dict( # Additional config of validation dataloader
videos_per_gpu=1), # Batch size of each single GPU during evaluation
test_dataloader=dict( # Additional config of test dataloader
videos_per_gpu=2), # Batch size of each single GPU during testing
train=dict( # Training dataset config
type=dataset_type,
ann_file=ann_file_train,
data_prefix=data_root,
pipeline=train_pipeline),
val=dict( # Validation dataset config
type=dataset_type,
ann_file=ann_file_val,
data_prefix=data_root_val,
pipeline=val_pipeline),
test=dict( # Testing dataset config
type=dataset_type,
ann_file=ann_file_test,
data_prefix=data_root_val,
pipeline=test_pipeline))
# optimizer
optimizer = dict(
# Config used to build optimizer, support (1). All the optimizers in PyTorch
# whose arguments are also the same as those in PyTorch. (2). Custom optimizers
# which are built on `constructor`, referring to "tutorials/5_new_modules.md"
# for implementation.
type='SGD', # Type of optimizer, refer to https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/optimizer/default_constructor.py#L13 for more details
lr=0.01, # Learning rate, see detail usages of the parameters in the documentation of PyTorch
momentum=0.9, # Momentum,
weight_decay=0.0001) # Weight decay of SGD
optimizer_config = dict( # Config used to build the optimizer hook
grad_clip=dict(max_norm=40, norm_type=2)) # Use gradient clip
# learning policy
lr_config = dict( # Learning rate scheduler config used to register LrUpdater hook
policy='step', # Policy of scheduler, also support CosineAnnealing, Cyclic, etc. Refer to details of supported LrUpdater from https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/lr_updater.py#L9
step=[40, 80]) # Steps to decay the learning rate
total_epochs = 100 # Total epochs to train the model
checkpoint_config = dict( # Config to set the checkpoint hook, Refer to https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/checkpoint.py for implementation
interval=5) # Interval to save checkpoint
evaluation = dict( # Config of evaluation during training
interval=5, # Interval to perform evaluation
metrics=['top_k_accuracy', 'mean_class_accuracy'], # Metrics to be performed
metric_options=dict(top_k_accuracy=dict(topk=(1, 3))), # Set top-k accuracy to 1 and 3 during validation
save_best='top_k_accuracy') # set `top_k_accuracy` as key indicator to save best checkpoint
eval_config = dict(
metric_options=dict(top_k_accuracy=dict(topk=(1, 3)))) # Set top-k accuracy to 1 and 3 during testing. You can also use `--eval top_k_accuracy` to assign evaluation metrics
log_config = dict( # Config to register logger hook
interval=20, # Interval to print the log
hooks=[ # Hooks to be implemented during training
dict(type='TextLoggerHook'), # The logger used to record the training process
# dict(type='TensorboardLoggerHook'), # The Tensorboard logger is also supported
])
# runtime settings
dist_params = dict(backend='nccl') # Parameters to setup distributed training, the port can also be set
log_level = 'INFO' # The level of logging
work_dir = './work_dirs/tsn_r50_1x1x3_100e_kinetics400_rgb/' # Directory to save the model checkpoints and logs for the current experiments
load_from = None # load models as a pre-trained model from a given path. This will not resume training
resume_from = None # Resume checkpoints from a given path, the training will be resumed from the epoch when the checkpoint's is saved
workflow = [('train', 1)] # Workflow for runner. [('train', 1)] means there is only one workflow and the workflow named 'train' is executed once
모델 (model)
# model settings
model = dict( # Config of the model
type='Recognizer2D', # Type of the recognizer
backbone=dict( # Dict for backbone
type='ResNet', # Name of the backbone
pretrained='torchvision://resnet50', # The url/site of the pretrained model
depth=50, # Depth of ResNet model
norm_eval=False), # Whether to set BN layers to eval mode when training
cls_head=dict( # Dict for classification head
type='TSNHead', # Name of classification head
num_classes=400, # Number of classes to be classified.
in_channels=2048, # The input channels of classification head.
spatial_type='avg', # Type of pooling in spatial dimension
consensus=dict(type='AvgConsensus', dim=1), # Config of consensus module
dropout_ratio=0.4, # Probability in dropout layer
init_std=0.01), # Std value for linear layer initiation
# model training and testing settings
train_cfg=None, # Config of training hyperparameters for TSN
test_cfg=dict(average_clips=None) # Config for testing hyperparameters for TSN.
)모델은 크게 backbone과 head로 이루어져있다.
Backbone은 ResNet50 기반인 걸 알 수 있고, pretrained에 torchvision://resnet50이라고 명시하면 torchvision의 기본 제공 weight를 다운받는다. 해당 weight는 ImageNet-pretrained이다.
Head는 TSNHead 클래스를 사용한다. mmaction\models\heads\tsn_head.py에 구현되어있다. GAP → consensus → FFN을 거친다. Softmax는 아직 안 하고 loss를 계산할 때 한다. Consensus는 temporal axis 방향으로 mean을 취하는 과정이다. 비디오 모델이라 추가된 것이라 보면 된다.

모델의 type인 Recognizer2D가 뭔지 궁금할 것이다. mmaction\models\recognizers\recognizer2d.py에 구현되어있다. 우리가 신경써야 할 것은 forward_train과 _do_test이다. 2D (conv) 기반 모델들의 abstract 한 연산이 구현되어있다. backbone과 cls_head에서 정의된 모델들에 imgs를 통과시켜준다. 2D 기반 모델들에 대한 기능을 더 추가하고 싶다면 이 클래스를 상속받으면 된다.

train_cfg에서는 cutmix [Zhang et al., ICLR 2017][arXiv], mixup [Yun et al., ICCV 2019][arXiv] 등의 blending을 추가할 수 있다. In-batch cutmix와 mixup은 거의 free boost인 데다가 performance gain도 상당하기 때문에 유용할 것이다.

test_cfg에서는 해당 config 파일을 가지고 test를 할 때(training 종료 시, 또는 test.py로 실행 시), --out [PATH] 옵션으로 pkl 파일을 생성할 수 있는데, 여기에 model의 어느 부분의 output을 넣을지 고를 수 있다.

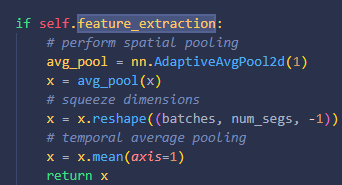
average_clips='prob': softmax를 통과한 확률값이 담긴다. Shape은 (# test set, # classes)이다.average_clips='score': logit이 담긴다. Shape은 똑같다.feature_extraction=True: Backbone을 통과한 feature를 뽑는다. GAP → consensus까지만 통과한 feature가 들어있고, 앞의 옵션들보다 우선순위가 높다.
Dataset 세팅
# dataset settings
dataset_type = 'RawframeDataset' # Type of dataset for training, validation and testing
data_root = 'data/kinetics400/rawframes_train/' # Root path to data for training
data_root_val = 'data/kinetics400/rawframes_val/' # Root path to data for validation and testing
ann_file_train = 'data/kinetics400/kinetics400_train_list_rawframes.txt' # Path to the annotation file for training
ann_file_val = 'data/kinetics400/kinetics400_val_list_rawframes.txt' # Path to the annotation file for validation
ann_file_test = 'data/kinetics400/kinetics400_val_list_rawframes.txt' # Path to the annotation file for testingdataset_type: 파이토치Dataset타입의 dataset getter이다.RawframeDataset의 경우mmaction\datasets\rawframe_dataset.py에 구현되어 있다. 정확한 나중에 설명할 것이다. 핵심 기능은 annotation 파일을 로드하여 input data path와 label을 indexing 해주는 것이다.- 그 밑의 스트링들: Input data와 annotation 파일의 경로를 지정해준다. 절대 경로로 써도 된다. 추천하는 방법은 repo 내에 symlink
'data/'를 만들어 위와 같이 상대경로로 쓰는 것이다.
img_norm_cfg = dict( # Config of image normalization used in data pipeline
mean=[123.675, 116.28, 103.53], # Mean values of different channels to normalize
std=[58.395, 57.12, 57.375], # Std values of different channels to normalize
to_bgr=False) # Whether to convert channels from RGB to BGR
train_pipeline = [ # List of training pipeline steps
dict( # Config of SampleFrames
type='SampleFrames', # Sample frames pipeline, sampling frames from video
clip_len=1, # Frames of each sampled output clip
frame_interval=1, # Temporal interval of adjacent sampled frames
num_clips=3), # Number of clips to be sampled
dict( # Config of RawFrameDecode
type='RawFrameDecode'), # Load and decode Frames pipeline, picking raw frames with given indices
dict( # Config of Resize
type='Resize', # Resize pipeline
scale=(-1, 256)), # The scale to resize images
dict( # Config of MultiScaleCrop
type='MultiScaleCrop', # Multi scale crop pipeline, cropping images with a list of randomly selected scales
input_size=224, # Input size of the network
scales=(1, 0.875, 0.75, 0.66), # Scales of width and height to be selected
random_crop=False, # Whether to randomly sample cropping bbox
max_wh_scale_gap=1), # Maximum gap of w and h scale levels
dict( # Config of Resize
type='Resize', # Resize pipeline
scale=(224, 224), # The scale to resize images
keep_ratio=False), # Whether to resize with changing the aspect ratio
dict( # Config of Flip
type='Flip', # Flip Pipeline
flip_ratio=0.5), # Probability of implementing flip
dict( # Config of Normalize
type='Normalize', # Normalize pipeline
**img_norm_cfg), # Config of image normalization
dict( # Config of FormatShape
type='FormatShape', # Format shape pipeline, Format final image shape to the given input_format
input_format='NCHW'), # Final image shape format
dict( # Config of Collect
type='Collect', # Collect pipeline that decides which keys in the data should be passed to the recognizer
keys=['imgs', 'label'], # Keys of input
meta_keys=[]), # Meta keys of input
dict( # Config of ToTensor
type='ToTensor', # Convert other types to tensor type pipeline
keys=['imgs', 'label']) # Keys to be converted from image to tensor
]img_norm_cfg: input 이미지의 normalization 파라미터들이다. 위는 kinetics400의 값이다.train_pipeline: 데이터 전처리 pipeline이다.
이미지 path로부터 로드하는 것부터 augmentation하는 것까지 포함한다. 해당 파이프라인을 통과하면results:dict가 되며 recognizer의 input으로 들어간다.
Validation, test 할 때는 각각 다른 pipeline을 쓴다. val_, test_로 되어있다. train에서는RandomCrop인 것이 test에서는CenterCrop인 식으로 다르다.
data = dict( # Config of data
videos_per_gpu=32, # Batch size of each single GPU
workers_per_gpu=2, # Workers to pre-fetch data for each single GPU
train_dataloader=dict( # Additional config of train dataloader
drop_last=True), # Whether to drop out the last batch of data in training
val_dataloader=dict( # Additional config of validation dataloader
videos_per_gpu=1), # Batch size of each single GPU during evaluation
test_dataloader=dict( # Additional config of test dataloader
videos_per_gpu=2), # Batch size of each single GPU during testing
train=dict( # Training dataset config
type=dataset_type,
ann_file=ann_file_train,
data_prefix=data_root,
pipeline=train_pipeline),
val=dict( # Validation dataset config
type=dataset_type,
ann_file=ann_file_val,
data_prefix=data_root_val,
pipeline=val_pipeline),
test=dict( # Testing dataset config
type=dataset_type,
ann_file=ann_file_test,
data_prefix=data_root_val,
pipeline=test_pipeline))위에서 설정한 string 변수들을 대입해준다. 위 변수 두 개는 설명이 조금 필요하다.
videos_per_gpu: GPU당 batch size이다. Total batch size는 (# gpus) x (videos_per_gpu)가 된다.workers_per_gpu: GPU당 worker 수, 전처리를 해줄 CPU 수이다. 쓰레드 수에 맞출 때 최적이다. ex) 4GPU, 24cores(48threads)를 할당받았다면12를 줄 때 최적이다.
Optimizer와 Scheduling
# optimizer
optimizer = dict(
# Config used to build optimizer, support (1). All the optimizers in PyTorch
# whose arguments are also the same as those in PyTorch. (2). Custom optimizers
# which are built on `constructor`, referring to "tutorials/5_new_modules.md"
# for implementation.
type='SGD', # Type of optimizer, refer to https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/optimizer/default_constructor.py#L13 for more details
lr=0.01, # Learning rate, see detail usages of the parameters in the documentation of PyTorch
momentum=0.9, # Momentum,
weight_decay=0.0001) # Weight decay of SGD
optimizer_config = dict( # Config used to build the optimizer hook
grad_clip=dict(max_norm=40, norm_type=2)) # Use gradient clipOptimizer의 파라미터를 넣는 부분이다. type에는 위와 같이 torch.optim에 있는 optimizer를 넣을 수도 있고, TSMOptimizerConstructor과 같이 customized optimizer를 넣을 수도 있다. Customize 하는 방법은 추후 다룰 것이다.
# learning policy
lr_config = dict( # Learning rate scheduler config used to register LrUpdater hook
policy='step', # Policy of scheduler, also support CosineAnnealing, Cyclic, etc. Refer to details of supported LrUpdater from https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/lr_updater.py#L9
step=[40, 80]) # Steps to decay the learning rate
total_epochs = 100 # Total epochs to train the model
checkpoint_config = dict( # Config to set the checkpoint hook, Refer to https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/checkpoint.py for implementation
interval=5) # Interval to save checkpoint
evaluation = dict( # Config of evaluation during training
interval=5, # Interval to perform evaluation
metrics=['top_k_accuracy', 'mean_class_accuracy'], # Metrics to be performed
metric_options=dict(top_k_accuracy=dict(topk=(1, 3))), # Set top-k accuracy to 1 and 3 during validation
save_best='top_k_accuracy') # set `top_k_accuracy` as key indicator to save best checkpoint
eval_config = dict(
metric_options=dict(top_k_accuracy=dict(topk=(1, 3)))) # Set top-k accuracy to 1 and 3 during testing. You can also use `--eval top_k_accuracy` to assign evaluation metrics
log_config = dict( # Config to register logger hook
interval=20, # Interval to print the log
hooks=[ # Hooks to be implemented during training
dict(type='TextLoggerHook'), # The logger used to record the training process
# dict(type='TensorboardLoggerHook'), # The Tensorboard logger is also supported
])
스케줄링 vars를 넣는 곳이다.
evaluationinterval: 단위는 에폭이다.metrics: 해당 metric들로 평가하여 stdout, .log, .json 파일로 출력한다.metric_options:mmaction\datasets\base.py에 metric들이 정의되어있는데 topk는 옵션을 추가로 받는다. 추가 옵션을 넣어준다.save_best: eval마다 해당 metric으로 모델을 평가하여 best이면 체크포인트를 저장한다. checkpoint_config와 별개이다.
eval_config: 얘는 이름을 잘못 지었다.test.py로 test 할 때 쓰는 옵션이다.train.py로 train 종료 후 test 할 때는 위에 있는 evaluation을 사용한다. 혼동 할 수 있다.output_config: 위 config엔 없다.test.py로 test 할 때 쓰는 옵션이다. Output(prob, score, feature)을 json, yaml, pickle로 출력 할 수 있다.

log_configinterval: 애는 step 단위이다. (데이터 크기 / 배치 사이즈)가 얘보다 작다면 로그가 씹힐 수 있다.by_epoch: 이 옵션을 주면 interval을 배치 당 step이 아니고 전체 training step 당으로 계산한다. 로그 찍어보면 이해할 수 있다.hooks: Text랑 Tensorboard hook밖에 안 써봤다. 웬만하면 tensorboard까지 켜는 걸 추천한다. 계산에 오래 걸리는 것도 아니고 메모리도 많이 안 먹는다.
Runtime 세팅
# runtime settings
dist_params = dict(backend='nccl') # Parameters to setup distributed training, the port can also be set
log_level = 'INFO' # The level of logging
work_dir = './work_dirs/tsn_r50_1x1x3_100e_kinetics400_rgb/' # Directory to save the model checkpoints and logs for the current experiments
load_from = None # load models as a pre-trained model from a given path. This will not resume training
resume_from = None # Resume checkpoints from a given path, the training will be resumed from the epoch when the checkpoint's is saved
workflow = [('train', 1)] # Workflow for runner. [('train', 1)] means there is only one workflow and the workflow named 'train' is executed once학습 외적인 요소들을 설정하는 곳이다.
dist_params: 주석에 써있는 게 전부이다.work_dir: 로그나 pth 등의 실험의 output들이 여기에 찍힌다.load_from: pretrained weight(.pth) 경로나 링크를 지정할 수 있다. 링크면 실행한 위치에 다운받는다.resume_from: ckpt 파일을 지정하면 해당 부분부터 다시 시작한다. 우리 교수님은 resume은 웬만하면 쓰지 말라고 하신다. Resume 과정을 거치면 디버깅 할 거리 +=1이라서 resume 할 바엔 그냥 첨부터 학습시키라고 하신다.workflow: 원래는[('train', 1), ('val', 1)]과 같이 사용해서 train 1에폭, val 1에폭과 같이 쓰는 것이었는데 비직관적이어서evaluation으로 옵션이 넘어갔다. 레거시 변수니까[('train', 1)]고정이라고 생각하면 편하다.
Config Import
Config 파일을 여러 개 만들다보면 중복되는 부분이 많고, 수정해야 할 시에 여러 파일들을 수정해야 된다. Config 파일을 import 하는 것으로 해결 가능하다.

Import 한 variable을 재정의 할 시, 오버라이딩 된다.
'Frameworks > mmaction2' 카테고리의 다른 글
| mmaction2 | 비디오 모델 학습 프레임워크 (0) | 2022.08.20 |
|---|
