빠르게 시작하기
Slurm Workload Manager - Quick Start User Guide
Quick Start User Guide Overview Slurm is an open source, fault-tolerant, and highly scalable cluster management and job scheduling system for large and small Linux clusters. Slurm requires no kernel modifications for its operation and is relatively self-co
slurm.schedmd.com
저자의 상세한 설명이 쓰여있다.
개요

Slurm은 리눅스 기반 클러스터에서 활용되는 스케줄러 또는 리소스 매니저이다. 서버 여러 대에 퍼져있는 GPU 등의 리소스를 효율적으로 쓸 수 있게 도와준다. 지도교수님이 박사 때 써보시고 감명을 받아 우리 랩 세팅을 하면서 구축했다. 우리 교수님 말고 신임 교수님이 두 분 더 계시는데, 노는 GPU를 최소화하기 위해 세 랩이 힘을 합쳐 클러스터를 구성했다. 랩마다 GPU 수요가 몰리는 기간이 다르니 서로 상부상조 하자는 취지이다. 초기에는 여러 애로사항이 있긴 했지만 구성이 되고 나니 매우 강력하다.
여담인데 세 랩이 클러스터를 구성하면서 교류가 매우 활발하다. 주당 1회 연합 논문읽기 스터디를 진행 중이며, 여러 프로젝트들을 교수님 두 분이서 지도해주시는 등 자원관리 외적으로도 장점이 많다.
2023/03/24 추가
우리 랩 클러스터 세팅에 슬럼이 성공적인 효과를 보면서 학과 클러스터를 구축하는 회의에서 교수님이 슬럼을 홍보했고 다른 교수님들께 장점이 효과적으로 어필되어 이전의 유료 클라우드 서비스를 중단하고 학과 클러스터도 슬럼으로 관리하게 됐다. 학과 클러스터는 9PFlops 급(3090급 250장)이고, 주변 사람들의 만족도는 굉장히 높다. (물론 관리자는 갈려나가야 한다.)
스케줄러의 필요성
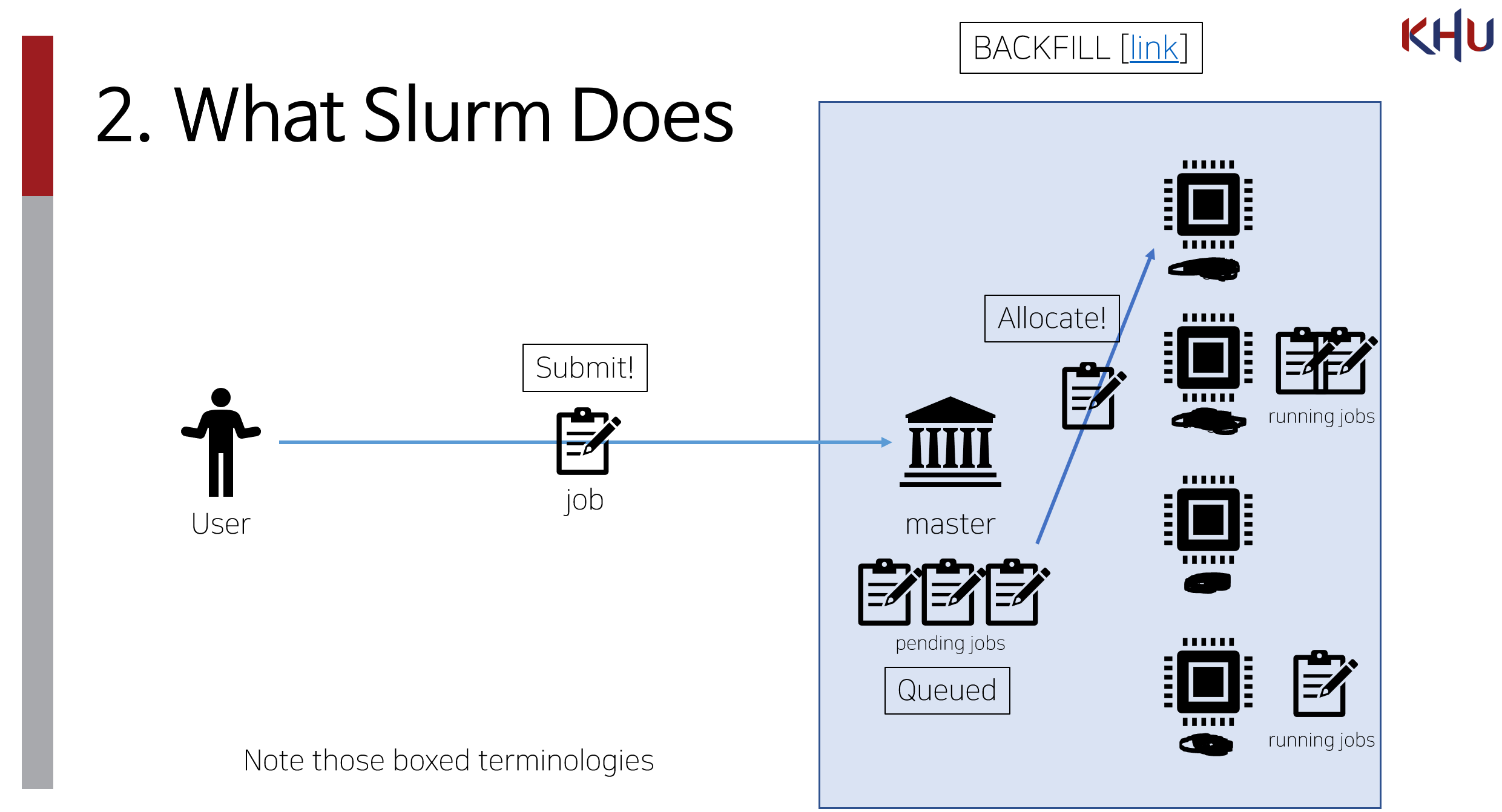
리소스 매니저/스케줄러는 다음과 같은 목표를 가질 경우 필요하다.
CPU/GPU등의 컴퓨팅 자원을
특정 시간 동안, 다른 유저의 방해를 받지 않고, 독점적으로 쓰게 하고 싶다.
유저가 자원을 요청하면 자원을 빌려주거나, 가용한 자원이 없으면 대기시킨다. 유저는 노드들을 돌며 일일이 nvidia-smi, htop을 찍어보면서 어느 GPU가 비었나 확인하지 않아도 되고, job을 돌려놓고 누가 내 GPU를 사용해 OOM이 뜨지 않을까 노심초사하지 않아도 된다. 또, 다른 사람이 자원을 쓰고 있을 때 수시로 nvidia-smi를 찍어보며 기다리지 않아도 된다.
기능
다음은 내가 써보고 감동한 기능 몇 개이다.
- 리소스 모니터링
간단한 명령어를 통해 현재 GPU를 누가 쓰고 있는지, job이 몇 개 대기 중인지, 노드 상태가 어떤지 등을 알 수 있다. 노드들을 돌면서 nvidia-smi 안 찍어봐도 된다. - 리소스 스케줄링
유저가 요구한 만큼의 자원이 있으면 바로 빌려주고, 없으면 대기시킨다. 자원이 비면 바로 할당시켜준다. 수시로 nvidia-smi 찍어보거나 job 돌리는 사람한테 언제 끝나냐고 물어보지 않아도 된다.
그리고 슬럼은 다른 리소스 매니저보다 더 유연한 스케줄링 정책을 갖고 있다. 대표적으로 backfilling이라는 건데 job들이 리소스를 기다리면서 줄 서있을 때 뒷사람이 할 일이 적다면 먼저 보내주는(할당시켜주는) 기능이다. - Fine-grained resource manging
다른 리소스 매니저에는 없는 굉장히 세부적인 리소스 제한 방식을 제공한다. 이를 통해 권한자 및 관리자는 더 세부적인 리소스 정책을 펼칠 수 있다. 예를 들어 우리 학교의 경우 대학원생의 경우 GPU 몇 개, CPU 몇 개, 메모리 몇 기가, 돌릴 수 있는 job 몇 개, 한번에 제출할 수 있는 job 몇 개, 잡 당 최대 시간 며칠... 그리고 학부연구생의 경우 ... 등 세부적으로 나눠서 관리할 수 있다. Accounting 기능으로 리소스를 수업 당, 팀 당으로도 제한 가능하다.다른 리소스 매니저, 특히 쿠버네티스는 CPU 코어(쓰레드)를 분리하여 job을 할당하는 기능을 지원하지 않는다.(2024.09.03 추가) cgroup으로 구현하면 되고 이미 드라이버도 있는 것 같다.
여담: 저렇게 아름답게 제한하기 위해서 필요한 명령어는 단 2~3줄 정도이다. 실제로 필요한 건 철저한 문서화를 통한 근거와 신뢰를 줄 수 있는 정책이다. "너가 알아서 대충 몇 개 줘"와 같이 정책에 큰 구멍이 있거나 정책에 관한 문서화가 잘 되어있지 않으면 유저 간 분쟁이 생긴다. 분쟁 해결에 제일 골머리를 앓았다. 슬럼은 정책의 자유도를 높여줄 뿐 분쟁을 해결해주진 않는다.
"슬럼은 정책 엔진이다." - Tim Wickberg, SchedMD - Job array
Job 하나를 여러 개 복사해서 제출할 수 있다. 완전히 똑같은 건 아니고 각 세션마다 JOB_ARRAY_TASK_ID라는 환경변수 값이 달라진다. 이를 이용해 hyper-parameter search를 할 수 있다. 아님 그냥 seed 만 달리해서 돌릴 수도 있다. - Prioritization
대기 중인 job이 많을 때 리소스가 비면 먼저 투입되는 순서를 정할 수 있다. 예: 논문 마감이 얼마 남지 않은 사람한테는 높은 priority를 주는 식으로 사용할 수 있다.
FairShare이라는 기능으로 유저의 최근 리소스 사용량을 기반으로 유저의 job 우선순위를 계산하게 할 수도 있다. GPU를 적게 사용한 사람이 job을 제출하면 줄 맨앞으로 보내주는 식이다. (하지만 우리는 GPU를 많이 사용하는 사람들은 계속 GPU를 많이 써야 하기 때문에 도입하진 않았다.) - Preemption
사용하도록 설정하면 높은 priority의 job이 제출되었을 때 강제로 running 중인 priority가 낮은 job을 중단시키고 투입시킬 수 있다. Gang scheduling이라고 한다. 진짜 그 갱 맞다. 중단된 job은 중단된 상태로 냅두거나 requeue라고 해서 자동으로 대기줄 맨 앞으로 보낼 수 있다. - Partition
여러 옵션이 pre-set 되어있는 노드 집합 정도로 생각하면 될 것 같다. Job을 제출할 때 반드시 파티션을 하나 이상 명시해야 한다. 파티션은 기본적으로 노드 집합이고, 해당 파티션을 쓸 수 있는 (유저)그룹 또는 슬럼의 기능인 account 등등을 명시해서 노드들을 분리하여 사용자 그룹이 사용할 수 있는 노드들을 제한하는 역할을 수행한다. 예: 컴공과 학생은 컴퓨터공학과 소속 노드만 사용 가능하게 하는 식으로 사용할 수 있다. - Requeue
Running 중인 job을 job 주인이 requeue 및 hold 시킬 수 있다. 누군가 급하게 잠깐 쓴다고 할 때 쓰면 좋다. ["B: 나 급한데 잠깐만 쓸게" -> "A: (job을 중단하며) 너 다 쓰면 알려줘" -> "B: 응 고마워" -> "A: 다 썼어?" -> "B: 아니 아직" -> "A: 언제 다 써?" -> ...] 안 해도 된다. - Job 예약 기능
제출된 job을 언제부터 돌릴지 예약할 수 있다. 예: "지금 job A를 돌려버리면 GPU 자리가 없으니까 좀이따 잘 때 시작하게 해놔야지~"
Docs가 상당히 잘 되어있다. (이쁘진 않다.) 그리고 기능도 훨씬 많다. 내가 지금까지 사용한 기능이 체감 상 전체 기능의 5% 정도 되는 것 같다. (2023/03/24 이제는 한 80% 정도 되는 것 같다)
안 되는 것
- Orchestration 및 배포
Microservice들(에 해당하는 job들)을 체계적으로 켜고 끄고가 안 된다. 따라서 서비스 배포 목적으로는 부적절하다. - VSCode-jupyter, GUI debugger
안 되는 건 아니고 좀 귀찮다. 모델을 짜거나 할 때 주피터나 디버거를 자주 쓰게 되는데 이때 GPU를 쓰겠다 하면 srun으로 GPU를 할당 받고 할당 된 노드에서 VSCode 등등을 또 켜야 한다. Open Ondemand 같은 서비스 쓰면 해결되긴 하지만 귀찮긴 하다.
Slurm vs. Kubernetes
이 글에선 둘 중 무엇이 scientific computation 등의 HPC workload에 적합한 지에 대해서 다룬다. LSF, Nomad, PBS 등은 다루지 않는다.
Slurm 편
- HPC on the Cloud: Slurm Cluster vs Kubernetes
만약 HPC로 활용할 목적이라면 온프레미스가 아니더라도 클라우드 위에 Slurm 등의 스케줄러가 필요하다. - Slurm and/or/vs Kubernetes
TOP500 슈퍼컴퓨터 중 반 이상, TOP10 중 6개가 Slurm을 사용 중이다.
델 HPC에서 쿠버와 Slurm을 합쳐서 서비스 하는 방법 연구, 쿠버가 있어도 슬럼은 필요하다. - 내 의견
메타는 Slurm 쓴다.
K8s 편
- 레딧 Yet another question on Kubernetes cluster vs HPC cluster (Slurm)
최근 빅테크들은 쿠버로 갈아타고 있다 (카더라) - Run:AI 최근에도 슬럼이 유효한가?
쿠버와의 비교라기보단 최근 AI/ML 워크로드 관점에서 봤을 때 Slurm에 없는 기능들을 언급한다.
→ 그래서 쿠버와 Slurm이 잘 합쳐진 Run:AI를 만들었다.
중립
- NVIDIA DeepOps로 GPU Cluster 구축하기
둘 다 써보신 분이라 장단점을 매우 명확하게 정리해주셨다. - SLURM vs Kubernetes vs Nomad
간단하게 정리되어있다. 살짝 쿠버 편인 것 같다.
추가적인 내 의견
HPC 목적으로 쿠버, Slurm 둘 다 써본 사람이 많지 않고, 쿠버는 데브옵스 쪽에서 무소불위의 SOTA이기 때문에 친숙한 사람들이 매우 많다. 그래서 HPC usage 쪽에서도 쿠버 손을 들어주는 쪽이 많은 것 같다. 하지만 쿠버는 유저에게 containerization 오버헤드를 강제하고, 보안 및 라우팅 목적의 네트워크 분리 등은 모델 학습 시 필요가 없다. 오히려 퍼포먼스에 방해가 된다. 이러한 batch job들은 로그 찍고, 체크포인트만 뱉어주면 된다. 그리고 Slurm의 backfill, multi-level QoS, Fairshare 등의 리소스 최적화 스케줄링은 쿠버의 로드밸런서, 서드파티 batch job 스케줄러 플러그인보다 HPC에 적합하다고 생각한다.
도커가 친숙해서 쿠버를 선택한다면 근거가 부족한 결정이다. 간단한 설정 후, Slurm에서도 도커 컨테이너를 사용할 수 있다.
'MLOPs > Slurm-user' 카테고리의 다른 글
| Slurm-user | Slurm 사용법: srun, sbatch로 리소스 할당 받고 Batch Job 제출하기 (1) | 2023.03.24 |
|---|
