Reference
[Bai et al., AAAI 2021] [paper] [code] DecAug: Out-of-Distribution Generalization via Decomposed Feature Representation and Semantic Augmentation
Authors
- HKUST
- Huawei Noah's Ark Lab
- Shanghai Jiao Tong Univ.
- Nanjing Univ.
- Haoyue Bai 1*† (intern)
- Rui Sun 2†
- Lanqing Hong 2
- Fengwei Zhou 2
- Nanyang Ye 3‡, Han-Jia Ye 4
- S.-H. Gary Chan 1
- Zhenguo Li 2
Summary
OOD generalization 문제의 핵심인 distribution shift를 두 가지 차원으로 decompose해서 생각해보고 이를 분리하여 학습하는 방법을 제시한 논문이다.
Motivation

Distribution shift에는 두 가지 차원이 있다.
- [Correlation shift] In-domain에서 input 이미지(의 attribute)와 라벨 간의 correlation이 train set과 test set에서 각각 다른 경우
예) Colored MNIST에서 train set의 4에는 빨강, 5에는 초록을 칠했지만, test set에서는 4에는 초록, 5에는 빨강을 칠한 경우 색 attribute와 라벨 간의 correlation이 반대 방향이다. - [Diversity(context) shift] 아예 이미지의 context(style, texture, 배경)가 다른 경우
예) 풀에서 찍은 강아지 vs 물가에서 찍은 강아지
많은 distribution shift method들은 한 번에 한 차원의 OOD generalization만을 고려한다. 그래서 한 dataset에서 잘 되는 method가 다른 dataset에서는 잘 되지 않는다. 예로, PACS에서 잘 되던 method가 Colored MNIST에서는 잘 안된다고 한다. PACS dataset은 diversity shift만 고려한 dataset이기 때문이다. 반면에 NICO(Non-I.I.D. Image dataset with COntexts)라는 dataset은 두 방향의 shift를 모두 고려한다. 일단 배경이 다양한 데다가 배경에 대한 라벨까지 달려 있어 train/test에서 쓸 배경을 분리할 수 있다. 이를 diversity shift로 생각하면 되고, 특정 배경에 correlate된 class가 많아(예: 새는 새장 안에 있는 사진이 많음) correlation shift도 고려한 것으로 볼 수 있다.


Generalization 논문들에선 이미지 distribution을 늘리는 방법으로 문제를 해결한다. 보통 generative와 augmentation 방법이 많이 쓰이는 것 같다. 하지만 generative는 매우 비싼 방법이기에 augmentation이 훨씬 많이 사용된다.
NICO dataset에는 배경에 관한 정보를 담고 있는 context-label이라는 추가적인 레이블이 존재한다. 이 정보를 이용해 우리가 원하는 object에 대한 feature와 별로 원하지 않는 context에 대한 feature를 분리하도록 학습시킬 수 있다. 그리고 분리된 context space에서 augmentation 하여 robust한 feature들을 학습했다.
Contributions
1. 기존의 방법들은 대다수가 한 가지 차원의 OOD만 고려했다는 것을 밝혀냈다.
2. Class와 context에 대한 feature를 구분하도록 학습시킬 수 있는 방법인 DecAug를 제시했다.
3. DecAug는 다양한 OOD task에서 SOTA를 찍었다.
Method (DecAug)

- $\mathcal{D}=\{(x_i, y_i, c_i)\}_{i=1}^N$: NICO dataset, $c_i$는 context-label
- $z_i = g_\theta(x_i)$: Backbone
- $z_i^1 = f_{\theta^1}(z_i)$: Category feature extractor
- $z_i^2 = f_{\theta^2}(z_i)$: Context feature extractor
- $h_{\phi^1}, h_{\phi^2}$: 각 브랜치의 최종 classifier
- Category branch: $y_i$를 맞히도록 학습, $\mathcal{L}_i = \text{CE}(
- Context branch: $c_i$를 맞히도록 학습
- Orthogonality: 두 loss에 대한 feature를 분리하도록 학습
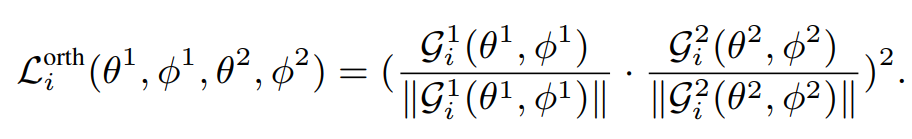
두 branch의 각각의 loss의 $$z_i$$에 대한 gradient의 cosine similarity 제곱이다. 백본이 뽑아낸 feature에서 category에 변화를 주는 방향, context에 변화를 주는 방향을 분리한다. 이상적으로는 Feature space를 2x2로 가르는 효과를 낸다. Gradient의 similarity가 아니라 feature map 자체의 similarity를 써도 된다. 하지만 ablation에서 gradient를 사용한 것이 효과가 더 좋았다.
- Semantic augmentation: 다양한 context를 학습시킴
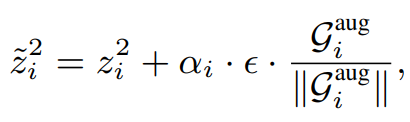
단순히 생각하면 adversarial sample을 찾는 과정이다. Context branch의 feature space에서 loss에 크게 반응하는(loss를 높이는) 곳으로 탐색한다.
내 생각) 단순히 adversarial sample이지만 semantic space에서 찾는 것이기 때문에 좀 더 의미있는 sample을 생성하지 않을까 생각한다. 예를 들면 아래와 같이 같은 풀밭 context여도 다른 structure를 가진 sample이 아닐까 생각한다.

- Concat: 최종 classifier랑 백본도 같이 학습시킨다. 백본 fine-tuning 여부에 대한 ablation도 있는데 하는 게 성능이 더 좋았다.
- $\mathcal{L}_i^\text{concat}(\theta, \theta^1, \theta^2, \phi) = \ell(h_\phi([z_i^1, \tilde{z}_i^2]),y_i)$
- $\mathcal{L}_i(\theta, \theta^1, \phi^1, \theta^2, \phi^2, \phi) \\= \mathcal{L}_i^{\text{concat}}(\theta, \theta^1, \theta^2, \phi) + \lambda^1 \cdot \mathcal{L}_i^1(\theta, \theta^1, \phi^1) + \lambda^2 \cdot \mathcal{L}_i^2(\theta, \theta^2, \phi^2) + \lambda^{\text{orth}} \cdot \mathcal{L}_i^{\text{orth}}(\theta^1, \phi^1, \theta^2, \phi^2)$
Experiment
Datasets
- The Colored MNIST Dataset
- 0-4은 $0$, 5-9은 $1$로 re-label
- $0$인 애들은 25%의 확률로 label이 $1$로 바뀜 (label corruption)
- Train(8-90%)과 test(10%) dataset에 다른 correlation을 줘서 색칠함
- The PACS Dataset
- 4 domains, 7 categories(dog, elephant, giraffe, guitar, horse, house, person)
- 한 domain만 빼서 validation에 사용함(leave-one-domain-out) ⇒ 3 domains for training, 1 domain for testing
- The NICO Dataset
- 19 classes with 10 or 9 different contexts (한 class에 9 or 10개의 context가 있다는 뜻인가봄)
Results

- DecAug 밑에 두 기법은 upper bound 성능이다. 거의 upper bound에 가까운 성능을 보여준다.
- 특히 JiGen과의 차이가 크다. 한 가지 차원의 domain shift만 고려해서 그런 것이라고 한다.

- 역시 SOTA를 찍었다.
- IRM과 Rex가 Colored MNIST와 달리 고전하는 모습을 보이는데 unstable feature를 제거하는 strong regularization때문이라고 한다. 실제 데이터는 MNIST보다 훨씬 unstable하기에 작동을 잘 못한다고 주장한다.

- 이 논문의 핵심인 NICO dataset에서도 SOTA를 찍었다.
- JiGen과의 margin은 그렇게 크지 않은 것 같다. 이에 대한 언급은 없었다.
Interpretability

Context branch는 category branch보다 배경에 좀 더 집중하는 모습을 보인다고 한다. 언뜻 보면 그런 것 같기도 한데 조금 무리한 주장이 아닐까 싶다.
Limitation
이 논문의 핵심은 NICO dataset의 context label이다. 이게 있어야만 가능한 학습법인 것 같다.